I’m happy to release Outbrain’s Propagator as open source. Propagator is a schema & data deployment tool which makes it easy to deploy, review, audit & fix deployments to your database servers.
What does multi-everything mean? It is:
- Multi-server: push your schema & data changes to multiple instances in parallel
- Multi-role: different servers have different schemas
- Multi-environment: recognizes the differences between development, QA, build & production servers
- Multi-technology: supports MySQL, Hive (Cassandra on the TODO list)
- Multi-user: allows users authenticated and audited access
- Multi-planetary: TODO
With dozens of database servers in our company (and these are master database servers), from development machines to testing machines, through build machines to production servers, and with a growing team of over 70 engineers, we faced the growing problem of controlling our database schema evolution. Controlling creation of tables, columns, keys, foreign keys; controlling creation of data that must be consistent across all servers became an infeasible task. Some changes were lost; some servers forgotten along the way, and inconsistencies blocked our development & deployments again and again.
We have reviewed schema-versioning tools (e.g. FlywayDB and Liquibase) only to conclude they solve a fraction of the problem. We looked at some GUI tools that promise to deliver the solution, but frankly any Windows Desktop GUI application is by definition the wrong tool for the job, and not (only) because of the “Windows” part.
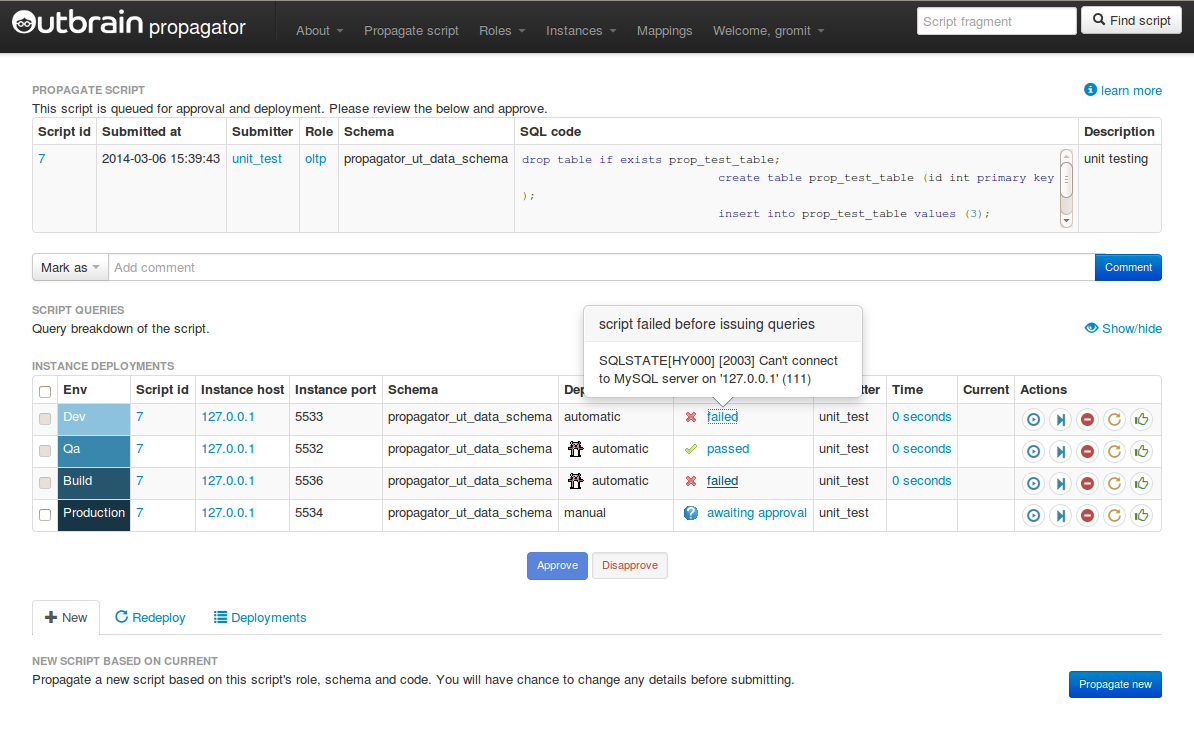
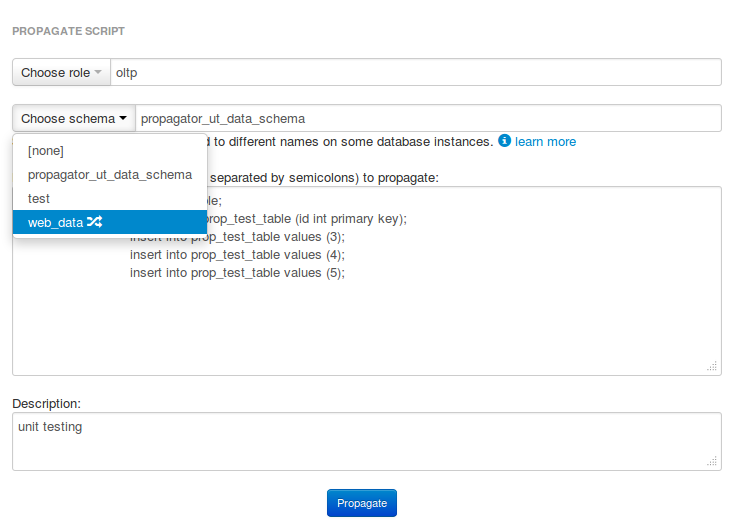
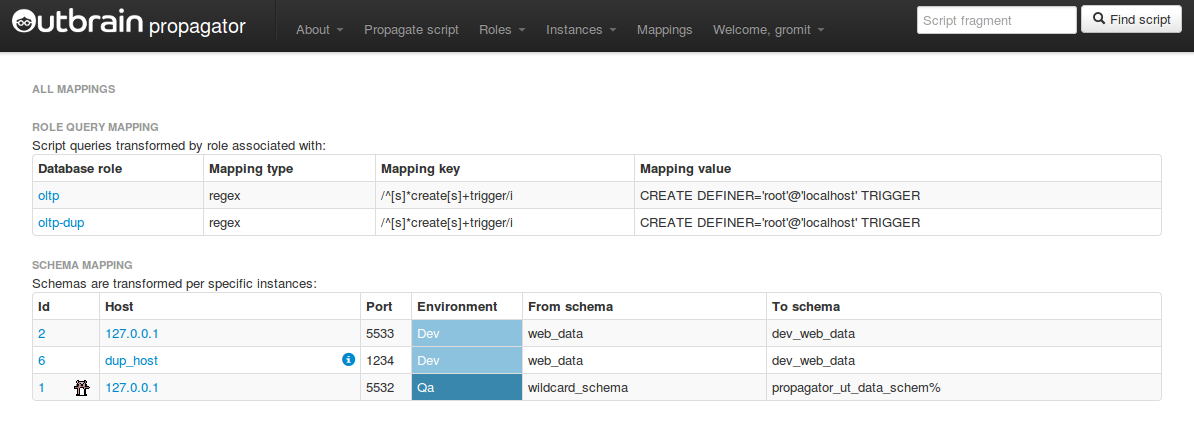
Not all deployments are the same. Not all servers are the same. You don’t ALTER a big table on production. You may be using different schema names on different servers. You may have multiple schemas on a single server with identical structure. You may wish to only deploy to some development servers, possibly to a test server, but not to all, and yet be able to pick up on where you left a few days later on to complete your deployment. Some deployments fail, and for various reasons (e.g. John created that table manually on this particular test server, so obviously you can’t CREATE it again), and you want to be able to skip it, or mark it as “OK”, or put some comments, or hint that you need assistance from a DBA. You want to be able to quickly add new servers to your deployment group.
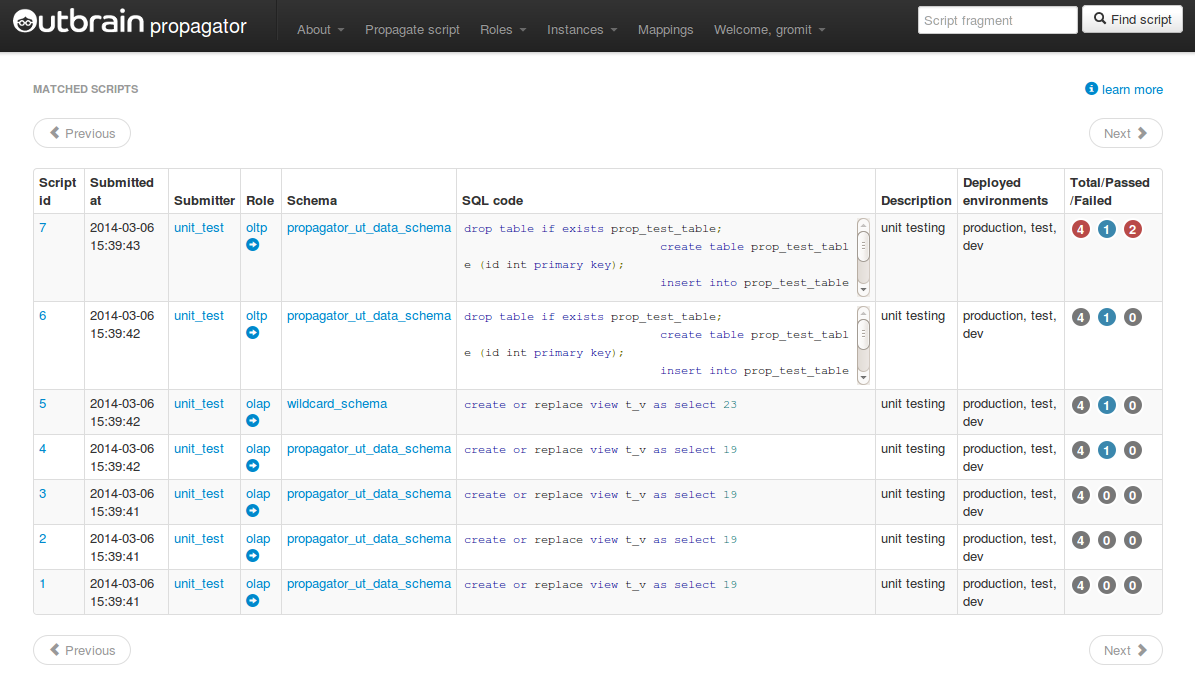
Above all, you want every single deployment to be fully audit-able. You want to know exactly who did what and when. If their deployment failed, you want to know that. You want to know why it failed. You want to be able to pick up and try it again, after your DBA found the problem. You want to be able to review yesterday’s deployments, and be able to contact Jane and say “hey, I see you hit a problem here; I know what the problem is; you should do this and that, then please try to deploy again”.
There’s so much more, but I’ll stop telling you what you want to have, since there’s a good manual available.
This is how Propagator came to be. For the past three months it has been in production use at our company. Our engineers used it to deploy hundreds of schema and data changes, and provided with tons of feedback in the form of bug reports, feature requests and general hints on easy of use and expected behaviour.
My company, Outbrain, is a strong supporter of open source, and we mutually agreed that this would make for a good open source solution. My company provided me with the resources and patience to polish it to the level of an open source release: a fully featured, stable, documented, visually appealing product.
Propagator is available on GitHub and is released under the Apache 2.0 license.
Some technical details
Propagator is a PHP application, running on top Apache. It uses MySQL as backend for maintaining both internal data (instances, ports, roles, …) as well as deployments status. On the frontend it uses Twitter Bootstrap, jQuery and all the usual suspects.
It is loosely forked off from Anemometer (get to know Anemometer if you haven’t already).
Setting it up
It’s mostly an “extract to apache, configure database access, put in some initial data” setup. There is some time to dwell on “putting the initial data”. Which servers you have? What environments? What kind of roles you have? You’ll need to set this up first.
The following are screenshots from the sample-phpunit-database. I can’t provide with a screenshot from our internal production service, but you can get the general picture.
Propagator is one of the tools discussed in my upcoming talk at Percona Live: MySQL DevOps @ Outbrain
6 thoughts on “Introducing Propagator: multi-everything deployment made easy”