I am unable to bring myself to trust the Seconds_behind_master value on SHOW SLAVE STATUS. Even with MySQL 5.5‘s CHANGE MASTER TO … MASTER_HEARTBEAT_PERIOD (good thing, applied when no traffic goes from master to slave) it’s easy and common to find fluctuations in Seconds_behind_master value.
And, when sampled by your favourite monitoring tool, this often leads to many false negatives.
At Outbrain we use HAProxy as proxy to our slaves, on multiple clusters. More about that in a future post. What’s important here is that our decision whether a slave enters or leaves a certain pool (i.e. gets UP or DOWN status in HAProxy) is based on replication lag. Taking slaves out when they are actually replicating well is bad, since this reduces the amount of serving instances. Putting slaves in the pool when they are actually lagging too much is bad as they contain invalid, irrelevant data.
To top it all, even when correct, the Seconds_behind_master value is practically irrelevant on 2nd level slaves. In a Master -> Slave1 -> Slave2 setup, what does it mean that Slave2 has Seconds_behind_master = 0? Nothing much to the application: Slave1 might be lagging an hour behind the master, or may not be replicating at all. Slave2 might have an hour’s data missing even though it says its own replication is fine.
None of the above is news, and yet many fall in this pitfall. The solution is quite old as well; it is also very simple: do your own heartbeat mechanism, at your favourite time resolution, and measure slave lag by timestamp you yourself updated on the master.
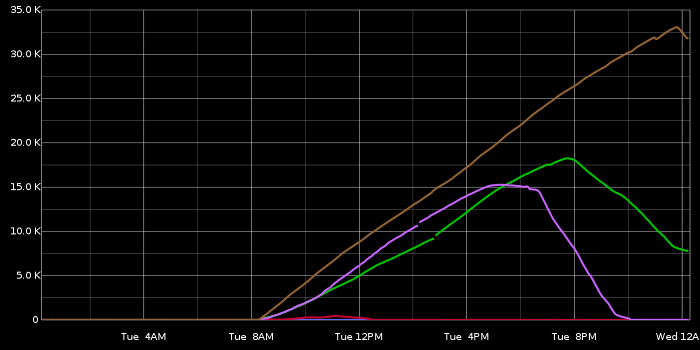
Maatkit/percona-toolkit did this long time ago with mk-heartbeat/pt-heartbeat. We’re doing it in a very similar manner. The benefit is obvious. Consider the following two graphs; the first shows Seconds_behind_master, the seconds shows our own Absolute_slave_lag measurement.
seconds_behind_master
absolute_slave_lag
The two graphs were taken simultaneously on a set of servers. Excuse me for not having same colours for same slaves, I blame it on graphite. Some small gaps are seen here that are irrelevant to our discussion (yes, we had some graphite delivery issues).
As you can see the Absolute_slave_lag does not (and cannot!) fluctuate. With our 10 second heartbeat resolution it always shows an accurate value. In fact, within the hearbeat resolution, it show the de facto replication lag. Let’s stress this one:
When you implement your own heartbeat mechanism, your own measured slave lag makes for the de facto slave replication lag within your heartbeat interval.
As another example, consider what happens when a slave stop replicating (i.e. some issued STOP SLAVE, or replication fails). The Seconds_behind_master value is NULL, which is a good indication to error, and easy to monitor. But how does it present visually? Not too well. It is usually just not rendered:
But, consider: a slave that STOPs for 1 minute for whatever reason is still only 1 minute behind master. That is, it is by 60 seconds up to date with master’s data. If we decide a slave should be serving for up to 5 minutes of lag, then our slave can still be used for serving for 4 more minutes! Seconds_behind_master does not provide us with helpful information. Absolute_slave_lag does. Consider the above system status when measured by Absolute_slave_lag:
We now get good insight on how far our slave is behind. Of course we monitor Seconds_behind_master to find out replication is not working; by our HAProxy only cares about Absolute_slave_lag.
How does it work?
Very similar to pt-heartbeat, there’s a dedicated table which we update with current timestamp. We read that timestamp on slave and compare with actual time on host.
We have these DDL:
create table my_heartbeat (
id int unsigned not null primary key,
master_ts timestamp,
update_by varchar(128) default NULL
);
create or replace view my_heartbeat_status_v as
select
master_ts,
now() as time_now,
timestampdiff(SECOND, master_ts, now()) as slave_lag_seconds,
update_by
from my_heartbeat
;
insert into my_heartbeat (id, master_ts, update_by) values (1, NOW(), 'init') on duplicate key update master_ts=NOW(), update_by=VALUES(update_by);
create event
update_heartbeat_event
on schedule every 10 second starts current_timestamp
on completion preserve
enable
do
insert into my_heartbeat (id, master_ts, update_by) values (1, NOW(), 'event_scheduler') on duplicate key update master_ts=NOW(), update_by=VALUES(update_by);
;
We use both event scheduler as well as external script to pump the heartbeat value.
On slave, utilize the view to:
select slave_lag_seconds from my_heartbeat_status_v
The above query answers: “how long ago was did I (the slave) get a timestamp update from the master?”. The result is correct within 10 seconds resolution, in our example.
Not new, but not well known. I hope the above provides you with better visibility into your replication lag.

One thought on “Seconds_behind_master vs. Absolute slave lag”