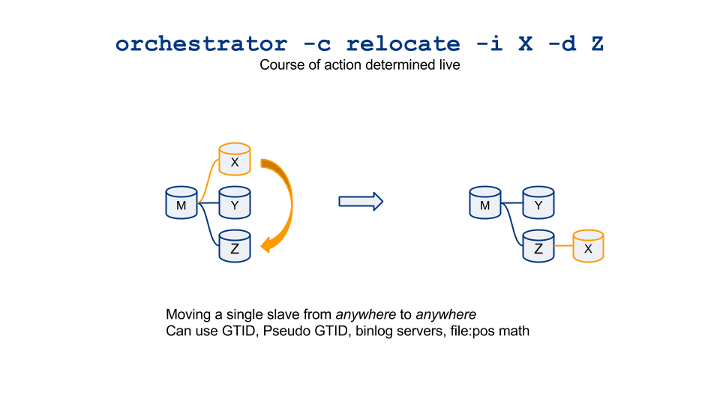
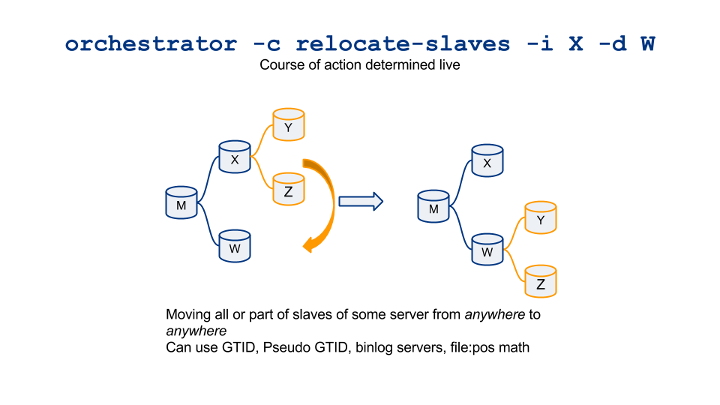
The more work on orchestrator, the more user input and the more production experience, the more insights I get into MySQL master recoveries. I’d like to share the complexities in correctly running general-purpose master failovers; from picking up the right candidates to finalizing the promotion.
The TL;DR is: we’re often unaware of just how things can turn at the time of failover, and the impact of every single decision we make. Different environments have different requirements, and different users wish to have different policies. Understanding the scenarios can help you make the right choice.
The scenarios and considerations below are ones I picked while browsing through the orchestrator code and through Issues and questions. There are more. There are always more scenarios.
I discuss “normal replication” scenarios below; some of these will apply to synchronous replication setups (Galera, XtraDB Cluster, InnoDB Cluster) where using cross DC, where using intermediate masters, where working in an evolving environment.
orchestrator-wise, please refer to “MySQL High Availability tools” followup, the missing piece: orchestrator, an earlier post. Some notions from that post are re-iterated here. Continue reading » “What’s so complicated about a master failover?”