If you’re running more than a few slaves in a replication topology, you might choose to use deeply nested replication: slaves replicating from other slaves at 2, 3 or even 4 levels. There are pros and cons to such topologies, discussed below.
A simple, small deep nested topology is depicted below (it is also a real production topology of ours):
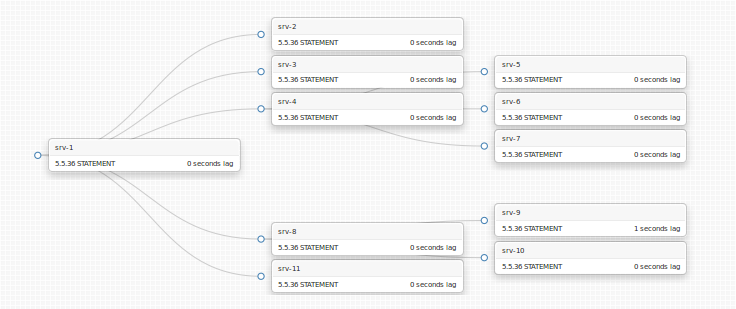
Two slaves, srv-4 and srv-8 act as local masters to yet other slaves. Why would we want to have this complexity?
Pros
- Reduce load on master: too many slaves replicating from single master means the master becomes loaded with serving the binary logs. Typically, when all slaves are up to date, this isn’t a big deal, since they all get served roughly the same entries, and caching works great. If not all are in sync, the master needs to look up different log entries and pays with more disk I/O.
- Reduce network load. We serve from three different data centres. Our master is in one DC, and our slaves are spread through all three. Inter-DC network is naturally slower; it is also more expensive, hence more easily saturated. Reducing cross-DC network is done across all our systems, including MySQL. srv-4, for example, could depict a slave that is a local master in its own DC, serving srv-5, srv-6, srv-7 all in the same DC, hence only using cross-DC network for one slave instead of four. A bit over-simplistic example but true.
- Failover. MHA does a good job at synchronizing slaves of same master by figuring out the missing binary log entries for each slave. It should do well within a single region, but I do not know that it would do the same cross region (I’m assuming the binlog entries copy should work, but I haven’t tried it cross region). In case of a disaster such as an entire DC going down (we actually had such a case a couple weeks ago; power went out for the entire DC), we have a designated master into which we can fail over in each other DC, and which contains enough slaves (from each remaining DCs) to keep serving. That it, we’re willing to skip the fancy syncing and just point to a newly promoted master, with the benefit that the entire replication topology under it is intact.
- Testing & upgrades. For example, I might want to upgrade to 5.6. Upgrading a slave from 5.5 to 5.6 is a good start; we look at replication and see that nothing gets broken. But how will our production master behave with 5.6? Put some more slaves under your newly upgraded 5.6 server and get a clearer picture. At some stage you might just promote this entire subtree as the new topology.
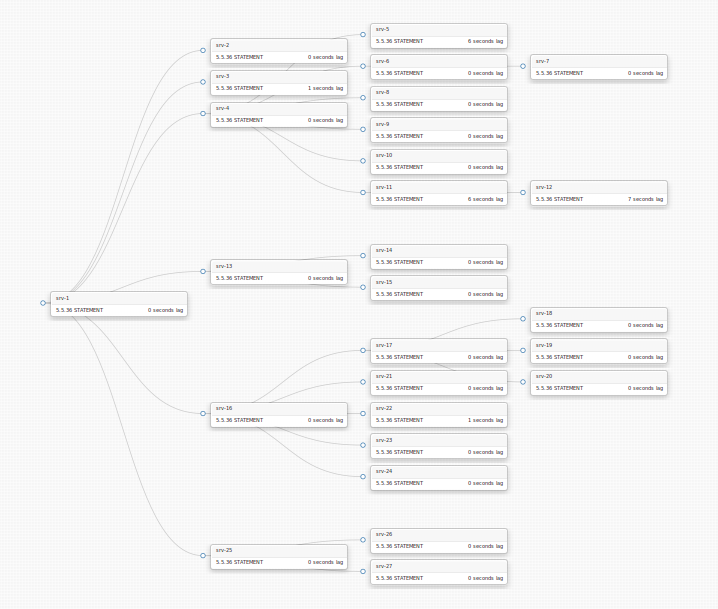
Here’s another topology; DC info is not depicted in this image, but you can guess what designated masters we have:
Cons
You must be willing to pay the price for the cons. These are:
- Accumulated replication lag: a local master that is lagging for some internal problem will cause all of its slaves to implicitly lag, even if those slaves machines aren’t busy at all.
- Corruption: if a local master gets corrupted, so do all of its slaves. This is not a problem if you’re using GTID. At the time of this writing very few companies I know of are using GTID, even though it’s been out for over a year. Like many others, we are still using good (?) old binary log file:position coordinates based replication.
Complex to maintain. Problem solved. The images above are real depictions of our topology (with some details obfuscated or changed). It’s a D3 graph that auto presents our topologies. To move slaves around we Drag & Drop them. This will shortly be announced as our latest open source release.
Hi Shlomi, very interesting as usual. I wonder how you menage the pt-table-checksum utility (if used), is the active master be compared to all slaves or do you use some work around in chain for all the slaves on your topology?
@Massimo,
We’re not using pt-table-checksum on a constant basis. If we do, then it’s of course a slave vs. its direct master.
When we suspect a slave becomes corrupted we destroy it and reseed from a trusted slave.
“Trust” is provided by our application level tests (hourly and daily) which do a lot of cross-referencing and checksuming (again, application-wise) of data. This is not issued against a specific slave but via pool, so every hour a different slave may be picked up.
The above does not cover every possible slave, since tests run within a certain DC. However the fact is that we don’t get slave corruptions, therefore our trust is high.
On certain occasions we run pt-table-sync on specific dates and times. We might start doing so on a scheduled basis.
Hi Shlomi, you do not talk about the problem of stalling replication on all slaves of an intermediate master if this intermediate master fails. To my understanding, MHA allows to promote a slave as a new master, but does not reconnect this new master upstream. To be able to do that, I think you need GTIDs (or maybe you solved this problem in another way).
@Jean,
I did note this: “a local master that is lagging for some internal problem will cause all of its slaves to implicitly lag” as well as “Corruption: if a local master gets corrupted, so do all of its slaves. “.
Like I said, you must be willing to pay this price on occasion. When such thing happens we reseed our lost servers.