We’re migrating some of our “vanilla” MySQL 5.5 servers to Percona Server 5.5. One of the major incentives is the crash-safe replication feature, allowing slaves to die (power failure) and resume replication without losing position in relay logs.
Whether or not we will migrate all our servers depends on further benchmarking; so far we’ve noticed unexpected results, but these are still premature to publish.
However the fact that we are using both MySQL & Percona Server has led us into a peculiar situation which I’d like to share. We reseed our servers via LVM snapshots. If we need a new machine, or have a corrupted slave, we capture an image of a running slave and duplicate it, a process which takes the better part of a day. This duplicates not only the data, of course, but also the relay logs, the relay-log.info file, master.info file, implying the position within the topology.
With crash safe replication this also means the transactional relay log position. Recap: crash safe replication writes, per transaction, the relay log status into ibdata1 file. So the relay log info in ibdata1 is in perfect alignment with your committed transactions. Upon server startup, Percona Server reads the info from ibdata1 and overwrites relay-log.info file (it completely disregards whatever was in that file prior to startup).
Can you guess what could get wrong here? Here’s the scenario we had; the same problem can unfold in different scenarios.
Take a look at the following topology:
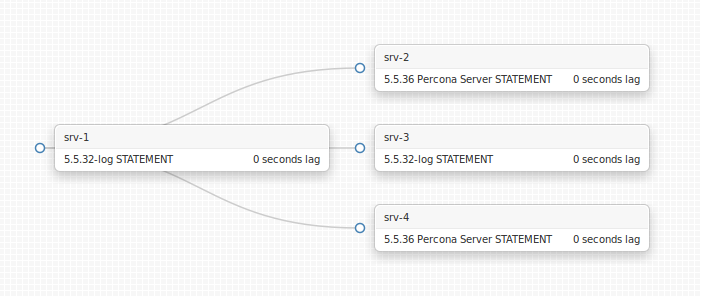
(this image is an actual online visualization of a replication topology; for purposes of this blog it’s a sandbox topology on my laptop. Please stand by for some very cool open source release announcement shortly)
We copied srv-2 (Percona Server) into srv-3 (MySQL). They both run well. A few days later we added srv-4 as Percona Server and (I’m cutting the story short here) reseeded it from srv-3. We started srv-4. Bam! Won’t replicate since it can’t find the required master logs.
Why? It was reseeded from srv-3 which was well replicating. It took less than 24 hours to complete the process and the master has 4 days of binary logs retention. Why would the new srv-4 fail to find the required logs on the master?
The catch here is that the Crash Safe Replication info residing in ibdata1 was copied from srv-2 to srv-3, where it was ignored (remember srv-3 is plain old MySQL and is ignorant of this info). This turned the info on srv-3 stale; it never got updated. Not only was it stale, it was also out of sync with srv-3‘s execution. But when data was copied to srv-4, Crash Safe Replication info was copied along, and srv-4 was happy to read this info upon strartup and use it to overwrite the perfectly valid relay-log.info file. By that time the master has long since purged the binary logs indicated in the newly rewritten relay-log.info file.
To some respect we were lucky, because this gave us immediate feedback and insight on what went wrong. Had replication found the logs on the master, it would have probably executed for a while, then crash on some Duplicate Key error where it would be much more difficult to track the origin of the problem.
Now that we are aware of the problem, we are more careful: you need to be careful once for each newly reseeded Percona Server instance, upon startup. We’ve added the following row to our /etc/init.d/mysql script, just before starting the server:
cp $datadir/relay-log.info $datadir/relay-log.info.pre-start
When we start a Percona Server for the first time we make sure to reset relay-log.info using relay-log.info.pre-start. We then go on with our lives. Until such time that all of our topology is composed of Percona Server, we have one more thing to be careful about.