I’m happy to announce the availability of Outbrain‘s Orchestrator: MySQL replication management & visualization tool.
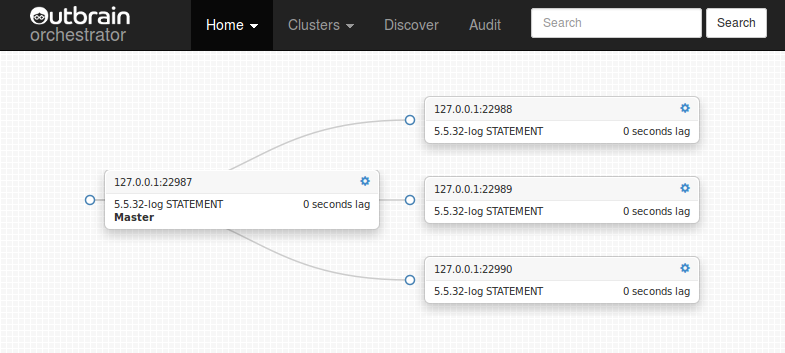
- Orchestrator reads your replication topologies (give it one server – be it master or slave – in each topology, and it will reveal the rest).
- It keeps a state of this topology.
- It can continuously poll your servers to get an up to date topology map.
- It visualizes the topology in a clear and slick D3 tree.
- It allows you to modify your topology; move slaves around. You can use the command line variation, the JSON API, or you can use the web interface.
Quick links: Orchestrator Manual, FAQ, Downloads
Nothing like nice screenshots
To move slaves around the topology (repoint a slave to a different master) through orchestrator‘s web interface, we use Drag and Drop,
just
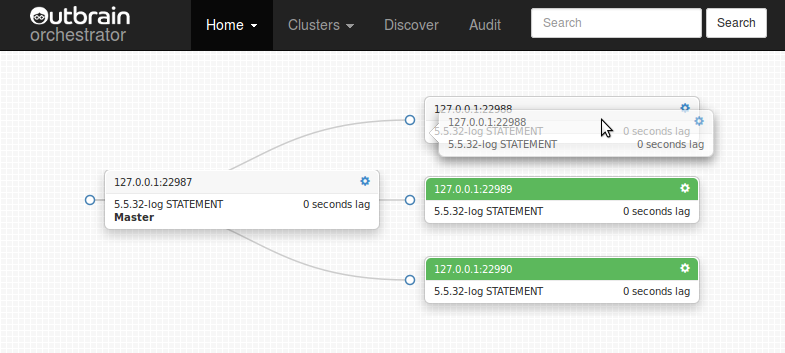
like
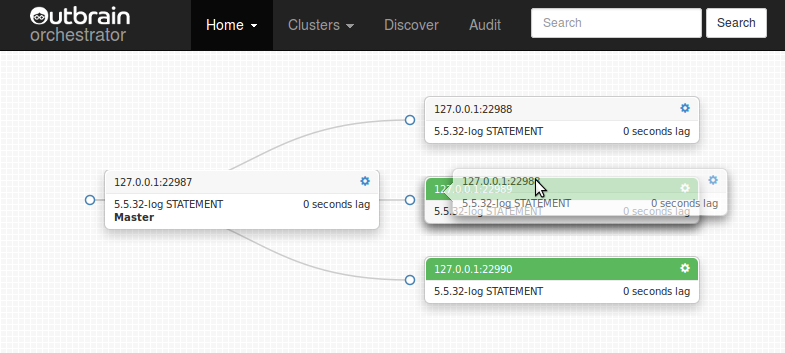
that.
Safety
Orchestrator keeps you safe. It does so by:
- Correctly calculating the binary log files & positions (aka coordinates) of the slave you’re moving, its current master, its new master; it properly stops, starts and stalls your replication till everything is in sync.
- Helping you to avoid shooting yourself in the leg. It will not allow moving a slave that uses STATEMENT based replication under a ROW based replication server. Or a 5.5 under a 5.6. Or anything under a server that doesn’t have binary logs. Or log_slave_updates. Or if one of the servers involed lags too much. Or more…
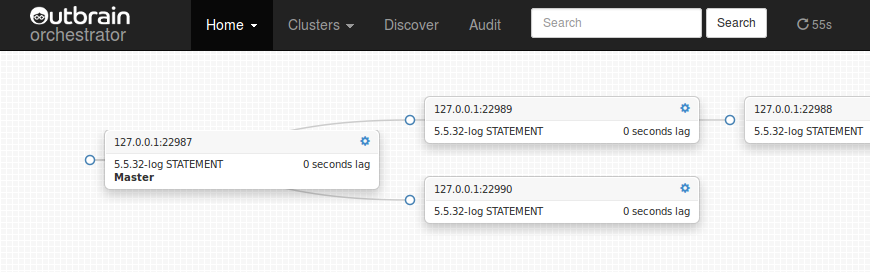
Visualization
It also points out a few problems, visually. While it is not – and will not be – a monitoring tool, it requires some replication status info for its own purposes. Too much lag? Replication not working? Server cannot be accessed? Server under maintenance? This all shows up in your topology. We use it a lot to get a holistic view over our current replication topologies status.
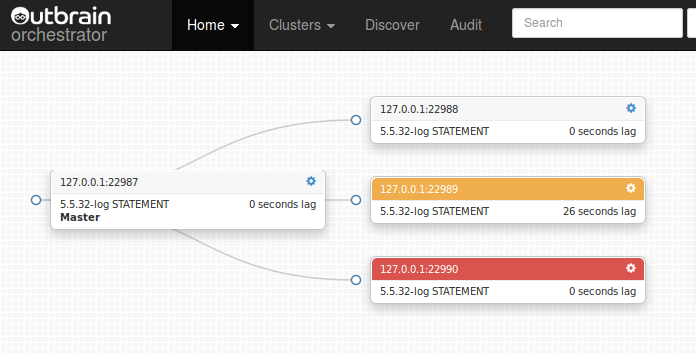
State
Orchestrator keeps the state of your topologies. Unlike other tools that will drill down from the master and just pick up on whatever’s connected right now, orchestrator remembers what used to be connected, too. If a slave is not replicating at this very moment, that does not mean it’s not part of the topology. Same for a MySQL service that has been temporarily stopped. And this includes all their slaves, if any. Until told otherwise (or until too much time passes and a server is assumed dead), orchestrator keeps the map intact.
Maintenance
Orchestrator supports a maintenance-mode state; it’s a flag saying “this server is in maintenance mode right now”. But this flag includes an owner and a reason for audit purposes. And while a server is under maintenance, orchestrator will disallow replication topology changes that include this server.
Audit
Operations performed via orchestrator are audited (well, almost all). You have a complete history on what slave has been moved from where to where; what server has been taken under maintenance and when, etc.
Automation
The most important thing is of course automating error-prone human sequences of actions. Repointing slaves is a mess (when you don’t have GTIDs). Automation saves time and greatly reduces the possibility that something goes wrong (of course never eliminates). We happen to use orchestrator at Outbrain on production, and twice in the past month had major events where orchestrator saved us many hours and worry.
Support
Orchestrator supports “standard” replication: log file:pos kind of replication. Non GTID, non-parallel. Good (?) old replication.
To quickly explain why not GTID: we’re using MySQL 5.5. We’ve had issues while evaluating 5.6; and besides, migrating to GTID is a mess (several solutions or proposed solutions seem to exist). On April’s Percona Live event, I realized only a few companies actually use MySQL 5.6, and a few of these use GTID. We’re not doing GTID (yet), as much as we would want to. Not there yet.
Read the FAQ for further questions on supported replication technologies.
How do you like it?
Orchestrator can run as a command line tool (no need for Web). It can server HTTP JSON API (no need for visualization) or it can server as HTTP web interface (no need to use command line options). Have it your way.
The technology stack
Orchestrator is written in Go, with Martini as web framework; MySQL as backend database; D3, jQuery & bootstrap for frontend.
License
Orchestrator is released as open source under the Apache 2.0 license and is available at: https://github.com/outbrain/orchestrator
Documentation
Read the Manual
Download
Get the bundled binary+web files tarball, RPM or DEB packages. Or just clone the project. It’s free.
Hi Jacky,
As per the FAQ: https://github.com/outbrain/orchestrator/wiki/FAQ
the answer is no. Please read through to learn about supported replication features.
Shlomi