orchestrator 3.0 Pre-Release is now available. Most notable are Raft consensus, SQLite backend support, orchestrator-client no-binary-required client script.
TL;DR
You may now set up high availability for orchestrator via raft consensus, without need to set up high availability for orchestrator‘s backend MySQL servers (such as Galera/InnoDB Cluster). In fact, you can run a orchestrator/raft setup using embedded SQLite backend DB. Read on.
orchestrator still supports the existing shared backend DB paradigm; nothing dramatic changes if you upgrade to 3.0 and do not configure raft.
orchestrator/raft
Raft is a consensus protocol, supporting leader election and consensus across a distributed system. In an orchestrator/raft setup orchestrator nodes talk to each other via raft protocol, form consensus and elect a leader. Each orchestrator node has its own dedicated backend database. The backend databases do not speak to each other; only the orchestrator nodes speak to each other.
No MySQL replication setup needed; the backend DBs act as standalone servers. In fact, the backend server doesn’t have to be MySQL, and SQLite is supported. orchestrator now ships with SQLite embedded, no external dependency needed.

In a orchestrator/raft setup, all orchestrator nodes talk to each other. One and only one is elected as leader. To become a leader a node must be part of a quorum. On a 3 node setup, it takes 2 nodes to form a quorum. On a 5 node setup, it takes 3 nodes to form a quorum.
Only the leader will run failovers. This much is similar to the existing shared-backend DB setup. However in a orchestrator/raft setup each node is independent, and each orchestrator node runs discoveries. This means a MySQL server in your topology will be routinely visited and probed by not one orchestrator node, but by all 3 (or 5, or what have you) nodes in your raft cluster.
Any communication to orchestrator must take place through the leader. One may not tamper directly with the backend DBs anymore, since the leader is the one authoritative entity to replicate and announce changes to its peer nodes. See orchestrator-client section following.
For details, please refer to the documentation:
The orchetrator/raft setup comes to solve several issues, the most obvious is high availability for the orchestrator service: in a 3 node setup any single orchestrator node can go down and orchestrator will reliably continue probing, detecting failures and recovering from failures.
Another issue solve by orchestrator/raft is network isolation, in particularly cross-DC, also refered to as fencing. Some visualization will help describe the issue.
Consider this 3 data-center replication setup. The master, along with a few replicas, resides on DC1. Two additional DCs have intermediate masters, aka local-masters, that relay replication to local replicas.
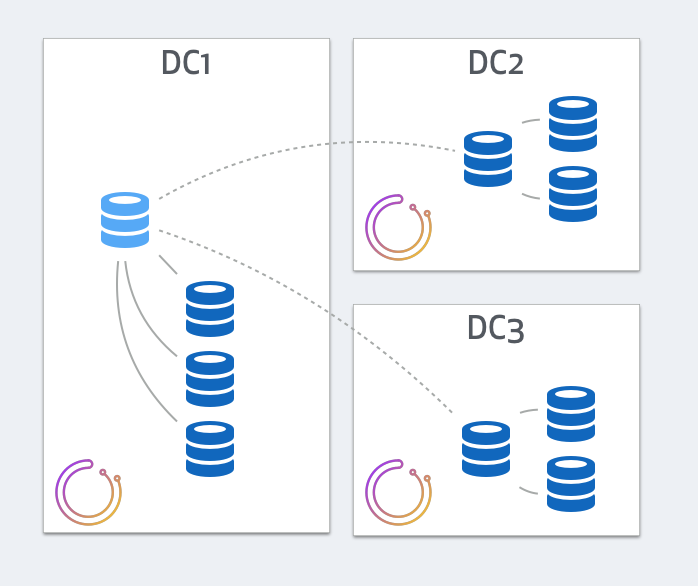
We place 3 orchestrator nodes in a raft setup, each in a different DC. Note that traffic between orchestrator nodes is very low, and cross DC latencies still conveniently support the raft communication. Also note that backend DB writes have nothing to do with cross-DC traffic and are unaffected by latencies.
Consider what happens if DC1 gets network isolated: no traffic in or out DC1
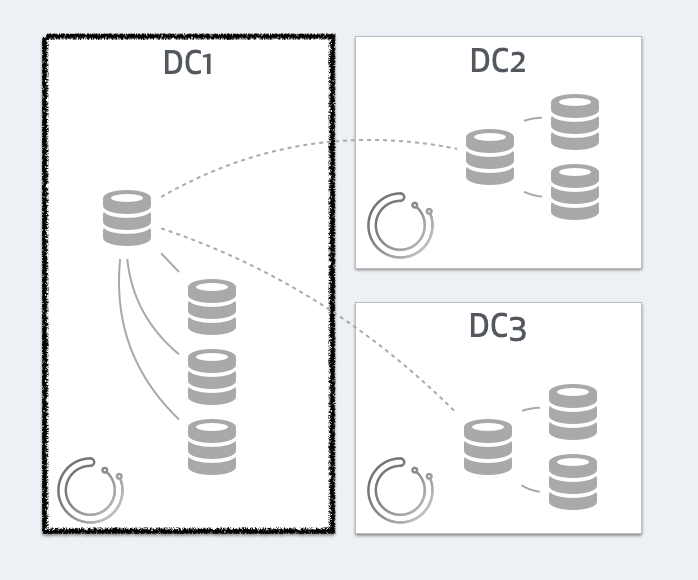
Each orchestrator nodes operates independently, and each will see a different state. DC1’s orchestrator will see all servers in DC2, DC3 as dead, but figure the master itself is fine, along with its local DC1 replicas:

However both orchestrator nodes in DC2 and DC3 will see a different picture: they will see all DC1’s servers as dead, with local masters in DC2 and DC3 having broken replication:
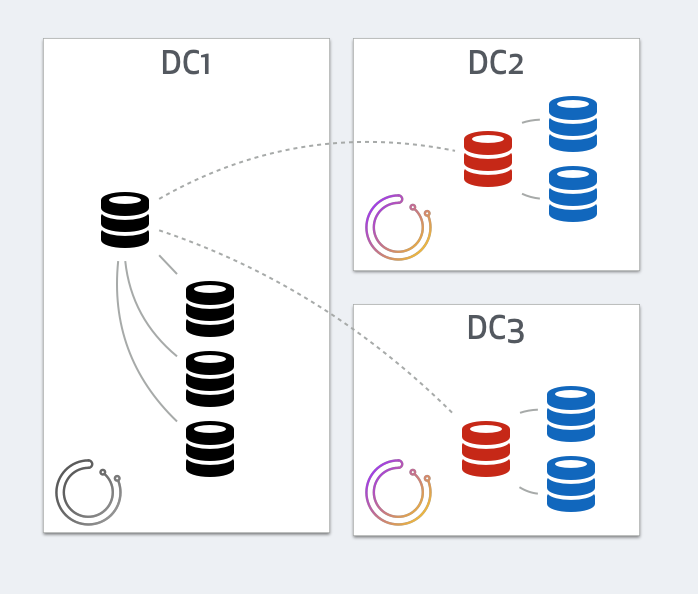
Who gets to choose?
In the orchestrator/raft setup, only the leader runs failovers. The leader must be part of a quorum. Hence the leader will be an orchestrator node in either DC2 or DC3. DC1’s orchestrator will know it is isolated, that it isn’t part of the quorum, hence will step down from leadership (that’s the premise of the raft consensus protocol), hence will not run recoveries.
There will be no split brain in this scenario. The orchestrator leader, be it in DC2 or DC3, will act to recover and promote a master from within DC2 or DC3. A possible outcome would be:

What if you only have 2 data centers?
In such case it is advisable to put two orchestrator nodes, one in each of your DCs, and a third orchestrator node as a mediator, in a 3rd DC, or in a different availability zone. A cloud offering should do well:
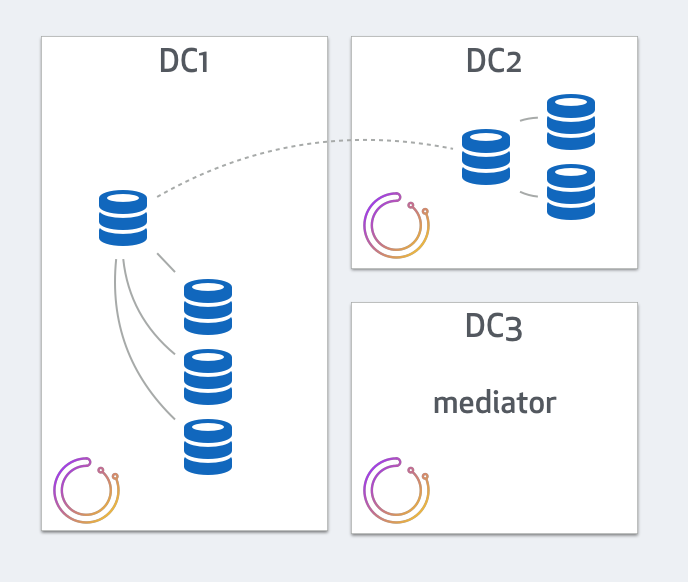
The orchestrator/raft setup plays nice and allows one to nominate a preferred leader.
SQLite
Suggested and requested by many, is to remove orchestrator‘s own dependency on a MySQL backend. orchestrator now supports a SQLite backend.
SQLite is a transactional, relational, embedded database, and as of 3.0 it is embedded within orchestrator, no external dependency required.
SQLite doesn’t replicate, doesn’t support client/server protocol. As such, it cannot work as a shared database backend. SQLite is only available on:
- A single node setup: good for local dev installations, testing server, CI servers (indeed,
SQLitenow runs inorchestrator‘s CI) orchestrator/raftsetup, where, as noted above, backend DBs do not communicate with each other in the first place and are each dedicated to their ownorchestratornode.
It should be pointed out that SQLite is a great transactional database, however MySQL is more performant. Load on backend DB is directly (and mostly linearly) affected by the number of probed servers. If you have 50 servers in your topologies or 500 servers, that matters. The probing frequency of course also matters for the write frequency on your backend DB. I would suggest if you have thousands of backend servers, to stick with MySQL. If dozens, SQLite should be good to go. In between is a gray zone, and at any case run your own experiments.
At this time SQLite is configured to commit to file; there is a different setup where SQLite places data in-memory, which makes it faster to execute. Occasional dumps required for durability. orchestrator may support this mode in the future.
orchestrator-client
You install orchestrator as a service on a few boxes; but then how do you access it from other hosts?
- Either
curltheorchestratorAPI - Or, as most do, install
orchestrator-clipackage, which includes theorchestratorbinary, everywhere.
The latter implies:
- Having the
orchestratorbinary installed everywhere, hence updated everywhere. - Having the
/etc/orchestrator.conf.jsondeployed everywhere, along with credentials.
The orchestrator/raft setup does not support running orchestrator in command-line mode. Reason: in this mode orchestrator talks directly to the shared backend DB. There is no shared backend DB in the orchestrator/raft setup, and all communication must go through the leader service. This is a change of paradigm.
So, back to curling the HTTP API. Enter orchestrator-client which mimics the command line interface, while running curl | jq requests against the HTTP API. orchestrator-client, however, is just a shell script.
orchestrator-client will work well on either orchestrator/raft or on your existing non-raft setups. If you like, you may replace your remote orchestrator installations and your /etc/orchestrator.conf.json deployments with this script. You will need to provide the script with a hint: the $ORCHESTRATOR_API environment variable should be set to point to the orchestrator HTTP API.
Here’s the fun part:
- You will either have a proxy on top of your
orchestratorservice cluster, and you wouldexport ORCHESTRATOR_API=http://my.orchestrator.service/api - Or you will provide
orchestrator-clientwith allorchestratornode identities, as inexport ORCHESTRATOR_API="https://orchestrator.host1:3000/api https://orchestrator.host2:3000/api https://orchestrator.host3:3000/api".
orchestrator-clientwill figure the identity of the leader and will forward requests to the leader. At least scripting-wise, you will not require a proxy.
Status
orchestrator 3.0 is a Pre-Release. We are running a mostly-passive orchestrator/raft setup in production. It is mostly-passive in that it is not in charge of failovers yet. Otherwise it probes and analyzes our topologies, as well as runs failure detection. We will continue to improve operational aspects of the orchestrator/raft setup (see this issue).
I’m continually impressed with the quality, thought, effort, and openness of mysql projects at GitHub. Thanks Shlomi et al. Looks great!
@Dane thank you for your kind words.