Pseudo GTID is a technique where we inject Globally Unique entries into MySQL, gaining GTID abilities without using GTID. It is supported by orchestrator and described in more detail here, here and here.
Quick recap: we can join two slaves to replicate from one another even if they never were in parent-child relationship, based on our uniquely identifiable entries which can be found in the slaves’ binary logs or relay logs. Having Pseudo-GTID injected and controlled by us allows us to optimize failovers into quick operations, especially where a large number of server is involved.
Ascending Pseudo-GTID further speeds up this process for delayed/lagging slaves.
Recap, visualized
(but do look at the presentation):
- Find last pseudo GTID in slave’s binary log (or last applied one in relay log)
- Search for exact match on new master’s binary logs
- Fast forward both through successive identical statements until end of slave’s applied entries is reached
- Point slave into cursor position on master
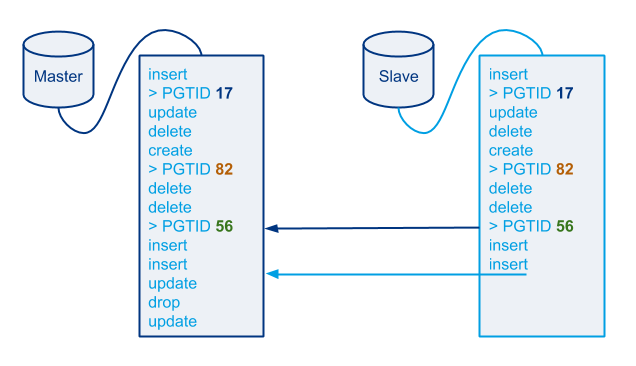
What happens if the slave we wish to reconnect is lagging? Or perhaps it is a delayed replica, set to run 24 hours behind its master?
The naive approach would expand bullet #2 into:
- Search for exact match on master’s last binary logs
- Unfound? Move on to previous (older) binary log on master
- Repeat
The last Pseudo-GTID executed by the slave was issued by the master over 24 hours ago. Suppose the master generates one binary log per hour. This means we would need to full-scan 24 binary logs of the master where the entry will not be found; to only be matched in the 25th binary log (it’s an off-by-one problem, don’t hold the exact number against me).
Ascending Pseudo GTID
Since we control the generation of Pseudo-GTID, and since we control the search for Pseudo-GTID, we are free to choose the form of Pseudo-GTID entries. We recently switched into using Ascending Pseudo-GTID entries, and this works like a charm. Consider these Pseudo-GTID entries:
drop view if exists `meta`.`_pseudo_gtid_hint__asc:55B364E3:0000000000056EE2:6DD57B85` drop view if exists `meta`.`_pseudo_gtid_hint__asc:55B364E8:0000000000056EEC:ACF03802` drop view if exists `meta`.`_pseudo_gtid_hint__asc:55B364ED:0000000000056EF8:06279C24` drop view if exists `meta`.`_pseudo_gtid_hint__asc:55B364F2:0000000000056F02:19D785E4`
The above entries are ascending in lexical order. The above is generated using a UTC timestamp, along with other watchdog/random values. For a moment let’s trust that our generation is indeed always ascending. How does that help us?
Suppose the last entry found in the slave is
drop view if exists `meta`.`_pseudo_gtid_hint__asc:55B364E3:0000000000056EE2:6DD57B85`
And this is what we’re to search on the master’s binary logs. Starting with the optimistic hope that the entry is in the master’s last binary log, we start reading. By nature of binary logs we have to scan them sequentially from start to end. As we read the binary log entries, we soon meet the first Pseudo-GTID injection, and it reads:
drop view if exists `meta`.`_pseudo_gtid_hint__asc:55B730E6:0000000000058F02:19D785E4`
At this stage we know we can completely skip scanning the rest of the binary log. Our entry will not be there: this entry is larger than the one we’re looking for, and they’ll only get larger as we get along in the binary log. It is therefore safe to ignore the rest of this file and move on to the next-older binary log on the master, to repeat our search there.
Binary logs where the entry cannot be in are only briefly examined: orchestrator will probably read no more than first 1,000 entries or so (can’t give you a number, it’s your workload) before giving up on the binary log.
On every topology chain we have 2 delayed replica slaves, to help us out in the case we make a grave mistake of DELETing the wrong data. These slaves would take, on some chains, 5-6 minutes to reconnect to a new master using Pseudo-GTID, since it required scanning many many GBs of binary logs. This is no longer the case; we’ve reduced scan time for such servers to about 25s at worst, and much quicker on average. There can still be dozens of binary logs to open, but all but one are given up very quickly. I should stress that those 25s are nonblocking for other slaves which are mote up to date than the delayed replicas.
Can there be a mistake?
Notice that the above algorithm does not require each and every entry to be ascending; it just compares the first entry in each binlog to determine whether our target entry is there or not. This means if we’ve messed up our Ascending order and injected some out-of-order entries, we can still get away with it — as long as those entries are not the first ones in the binary log, nor are they the last entries executed by the slave.
But why be so negative? We’re using UTC timestamp as the major sorting order, and inject Pseudo-GTID every 5 seconds; even with leap second we’re comfortable.
On my TODO is to also include a “Plan B” full-scan search: if the Ascending algorithm fails, we can still opt for the full scan option. So there would be no risk at all.
Example
We inject Pseudo-GTID via event-scheduler. These are the good parts of the event definition:
create event if not exists
create_pseudo_gtid_event
on schedule every 5 second starts current_timestamp
on completion preserve
enable
do
begin
set @connection_id := connection_id();
set @now := now();
set @rand := floor(rand()*(1 << 32));
set @pseudo_gtid_hint := concat_ws(':', lpad(hex(unix_timestamp(@now)), 8, '0'), lpad(hex(@connection_id), 16, '0'), lpad(hex(@rand), 8, '0'));
set @_create_statement := concat('drop ', 'view if exists `meta`.`_pseudo_gtid_', 'hint__asc:', @pseudo_gtid_hint, '`');
PREPARE st FROM @_create_statement;
EXECUTE st;
DEALLOCATE PREPARE st;
We accompany this by the following orchestrator configuration:
"PseudoGTIDPattern": "drop view if exists .*?`_pseudo_gtid_hint__", "PseudoGTIDMonotonicHint": "asc:",
“PseudoGTIDMonotonicHint” notes a string; if that string (“asc:”) is found in the slave’s Pseudo-GTID entry, then the entry is assumed to have been injected as part of ascending entries, and the optimization kicks in.
The Manual has more on this.
One thought on “Pseudo GTID, ASCENDING”