This post sums up some of my work on MySQL resilience and high availability at Booking.com by presenting the current state of automated master and intermediate master recoveries via Pseudo-GTID & Orchestrator.
Booking.com uses many different MySQL topologies, of varying vendors, configurations and workloads: Oracle MySQL, MariaDB, statement based replication, row based replication, hybrid, OLTP, OLAP, GTID (few), no GTID (most), Binlog Servers, filters, hybrid of all the above.
Topologies size varies from a single server to many-many-many. Our typical topology has a master in one datacenter, a bunch of slaves in same DC, a slave in another DC acting as an intermediate master to further bunch of slaves in the other DC. Something like this, give or take:
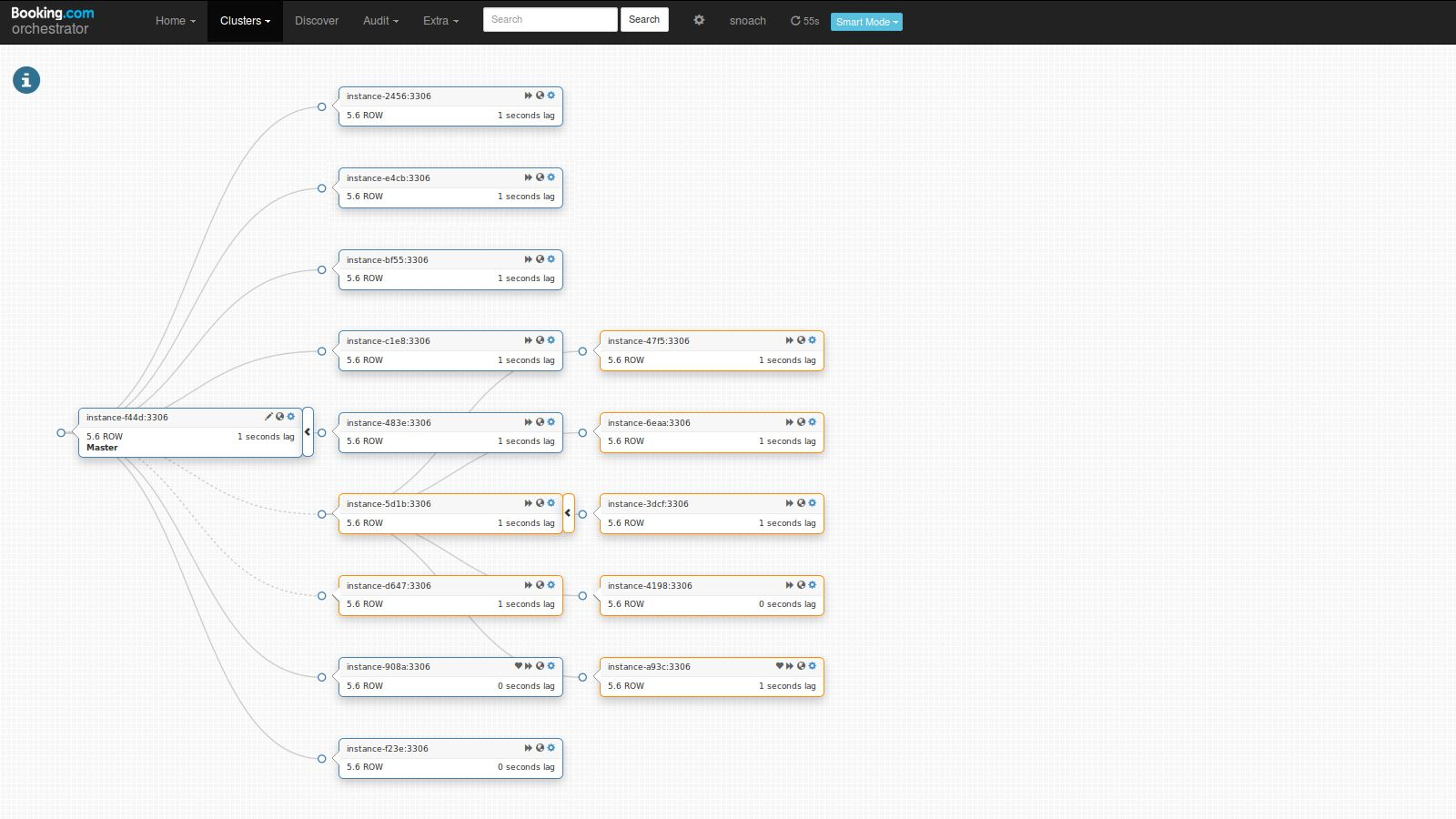
However as we are building our third data center (with MySQL deployments mostly completed) the graph turns more complex.
Two high availability questions are:
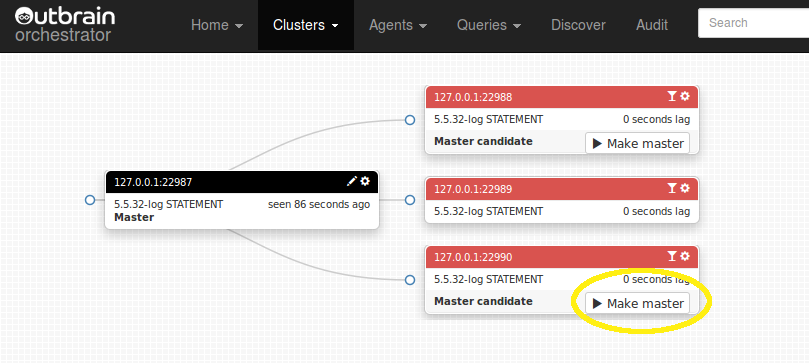
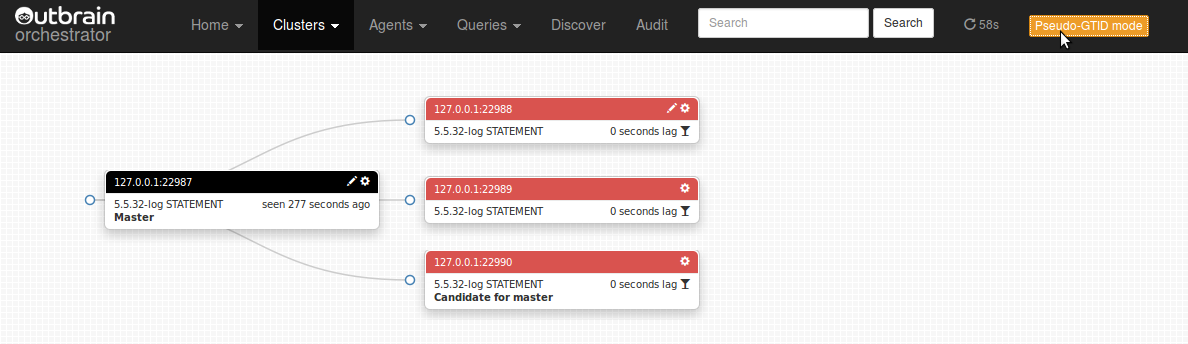
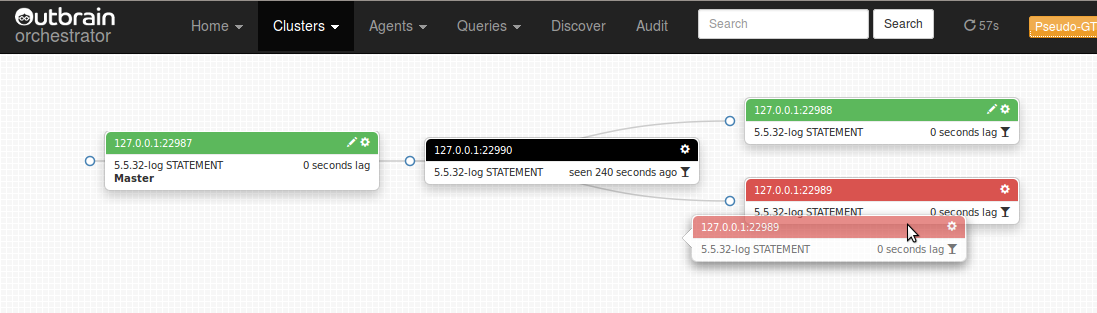
- What happens when an intermediate master dies? What of all its slaves?
- What happens when the master dies? What of the entire topology?
This is not a technical drill down into the solution, but rather on overview of the state. For more, please refer to recent presentations in September and April.
At this time we have:
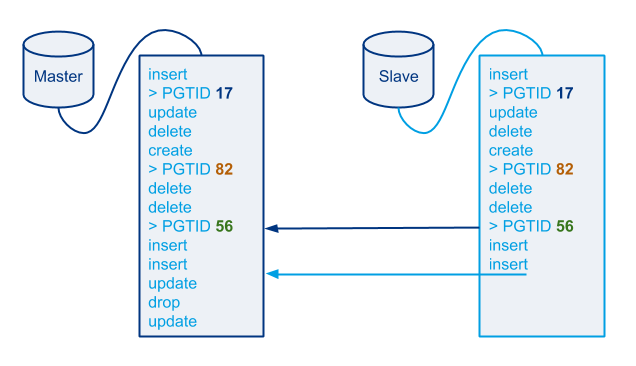
- Pseudo-GTID deployed on all chains
- Injected every 5 seconds
- Using the monotonically ascending variation
- Pseudo-GTID based automated failover for intermediate masters on all chains
- Pseudo-GTID based automated failover for masters on roughly 30% of the chains.
- The rest of 70% of chains are set for manual failover using Pseudo-GTID.
Pseudo-GTID is in particular used for:
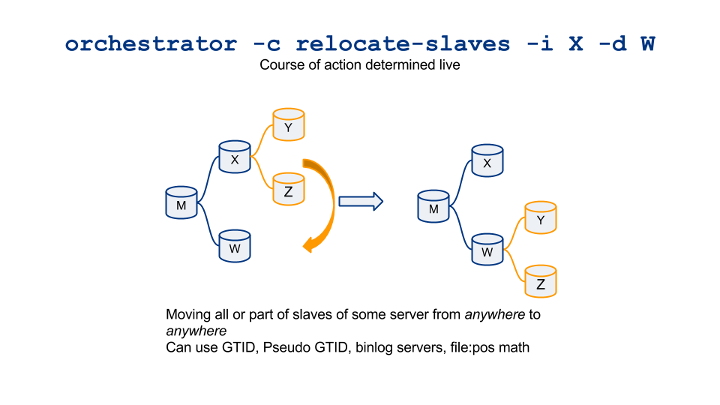
- Salvaging slaves of a dead intermediate master
- Correctly grouping and connecting slaves of a dead master
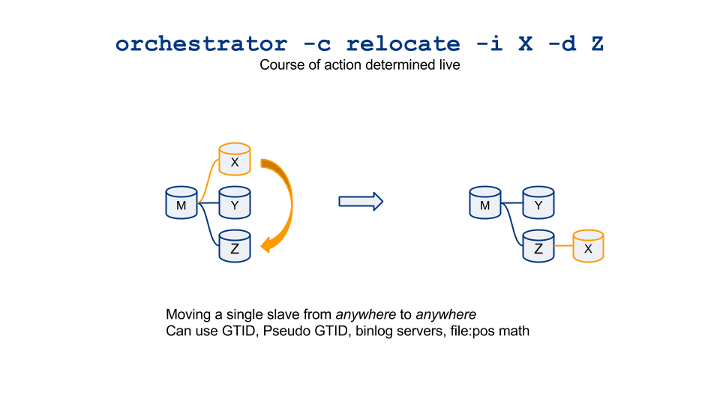
- Routine refactoring of topologies. This includes:
- Manual repointing of slaves for various operations (e.g. offloading slaves from a busy box)
- Automated refactoring (for example, used by our automated upgrading script, which consults with orchestrator, upgrades, shuffles slaves around, updates intermediate master, suffles back…)
- (In the works), failing over binlog reader apps that audit our binary logs.
Continue reading » “State of automated recovery via Pseudo-GTID & Orchestrator @ Booking.com”