Or: How do you reach the conclusion your MySQL master/intermediate-master is dead and must be recovered?
This is an attempt at making a holistic diagnosis of our replication topologies. The aim is to cover obvious and not-so-obvious crash scenarios, and to be able to act accordingly and heal the topology.
At Booking.com we are dealing with very large amounts of MySQL servers. We have many topologies, and many servers in each topology. See past numbers to get a feel for it. At these numbers failures happen frequently. Typically we would see normal slaves failing, but occasionally — and far more frequently than we would like to be paged for — an intermediate master or a master would crash. But our current (and ever in transition) setup also include SANs, DNS records, VIPs, any of which can fail and bring down our topologies.
Tackling issues of monitoring, disaster analysis and recovery processes, I feel safe to claim the following statements:
- The fact your monitoring tool cannot access your database does not mean your database has failed.
- The fact your monitoring tool can access your database does not mean your database is available.
- The fact your database master is unwell does not mean you should fail over.
- The fact your database master is alive and well does not mean you should not fail over.
Bummer. Let’s review a simplified topology with a few failure scenarios. Some of these scenarios you will find familiar. Some others may be caused by setups you’re not using. I would love to say I’ve seen it all but the more I see the more I know how strange things can become.
We will consider the simplified case of a master with three replicas: we have M as master, A, B, C as slaves.
A common monitoring scheme is to monitor each machine’s IP, availability of MySQL port (3306) and responsiveness to some simple query (e.g. “SELECT 1”). Some of these checks may run local to the machine, others remote.
Now consider your monitoring tool fails to connect to your master.
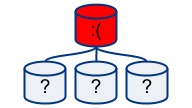
I’ve marked the slaves with question marks as the common monitoring schema does not associate the master’s monitoring result to the slaves’. Can you safely conclude your master is dead? Are your feeling comfortable with initiating a failover process? How about:
- Temporary network partitioning; it just so happens that your monitoring tool cannot access the master, though everyone else can.
- DNS/VIP/name cache/name resolving issue. Sometimes similar to the above; does you monitoring tool host think the master’s IP is what it really is? Has something just changed? Some cache expired? Some cache is stale?
- MySQL connection rejection. This could be due to a serious “Too many connections” problem on the master, or due to accidental network noise.
Now consider the following case: a first tier slave is failing to connect to the master:

The slave’s IO thread is broken; do we have a problem here? Is the slave failing to connect because the master is dead, or because the slave itself suffers from a network partitioning glitch?
A holistic diagnosis
In the holistic approach we couple the master’s monitoring with that of its direct slaves. Before I continue to describe some logic, the previous statement is something we must reflect upon.
We should associate the master’s state with that of its direct slaves. Hence we must know which are its direct slaves. We might have slaves D, E, F, G replicating from B, C. They are not in our story. But slaves come and go. Get provisioned and de-provisioned. They get repointed elsewhere. Our monitoring needs to be aware of the state of our replication topology.
My preferred tool for the job is orchestrator, since I author it. It is not a standard monitoring tool and does not serve metrics; but it observes your topologies and records them. And notes changes. And acts as a higher level failure detection mechanism which incorporates the logic described below.
We continue our discussion under the assumption we are able to reliably claim we know our replication topology. Let’s revisit our scenarios from above and then add some.
We will further only require MySQL client protocol connection to our database servers.
Dead master
A “real” dead master is perhaps the clearest failure. MySQL has crashed (signal 11); or the kernel panicked; or the disks failed; or power went off. The server is really not serving. This is observed as:
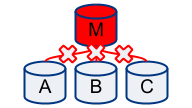
In the holistic approach, we observe that:
- We cannot reach the master (our MySQL client connection fails).
- But we are able to connect to the slaves A, B, C
- And A, B, C are all telling us they cannot connect to the master
We have now cross referenced the death of the master with its three slaves. Funny thing is the MySQL server on the master may still be up and running. Perhaps the master is suffering from some weird network partitioning problem (when I say “weird”, I mean we have it; discussed further below). And perhaps some application is actually still able to talk to the master!
And yet our entire replication topology is broken. Replication is not there for beauty; it serves our application code. And it’s turning stale. Even if by some chance things are still operating on the master, this still makes for a valid failover scenario.
Unreachable master
Compare the above with:
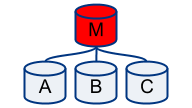
Our monitoring scheme cannot reach our master. But it can reach the slaves, an they’re all saying: “I’m happy!”
This gives us suspicion enough to avoid failing over. We may not actually have a problem: it’s just us that are unable to connect to the master.
Right?
There are still interesting use cases. Consider the problem of “Too many connections” on the master. You are unable to connect; the application starts throwing errors; but the slaves are happy. They were there first. They started replicating at the dawn of time, long before there was an issue. Their persistent connections are good to go.
Or the master may suffer a deadlock. A long, blocking ALTER TABLE. An accidental FLUSH TABLES WITH READ LOCK. Or whatever occasional bug we hit. Slaves are still connected; but new connections are hanging; and your monitoring query is unable to process.
And still our holistic approach can find that out: as we are able to connect to our slaves, we are also able to ask them: well what have your relay logs have to say about this? Are we progressing in replication position? Do we actually find application content in the slaves’ relay logs? We can do all this via MySQL protocol (“SHOW SLAVE STATUS”, “SHOW RELAYLOG EVENTS”).
Understanding the topology gives you greater insight into your failure case; you have increasing leevels of confidentiality in your analysis. Strike that: in your automated analysis.
Dead master and slaves
They’re all gone!
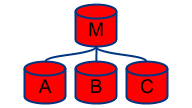
You cannot reach the master and you cannot reach any of its slaves. Once you are able to associate your master and slaves you can conclude you either have a complete DC power failure problem (or is this cross DC?) or you are having a network partitioning problem. Your application may or may not be affected — but at least you know where to start. Compare with:
Failed DC
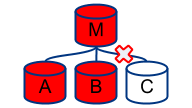
I’m stretching it now, because when a DC fails all the red lights start flashing. Nonetheless, if M, A, B are all in one DC and C is on another, you have yet another diagnosis.
Dead master and some slaves

Things start getting complicated when you’re unable to get an authorized answer from everyone. What happens if the master is dead as well as one of its slaves? We previously expected all slaves to say “we cannot replicate”. For us, master being unreachable, some slaves being dead and all other complaining on IO thread is good enough indication that the master is dead.
All first tier slaves not replicating
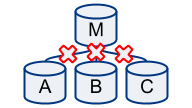
Not a failover case, but certainly needs to ring the bells. All master’s direct slaves are failing replication on some SQL error or are just stopped. Our topology is turning stale.
Intermediate masters
With intermediate master the situation is not all that different. In the below:
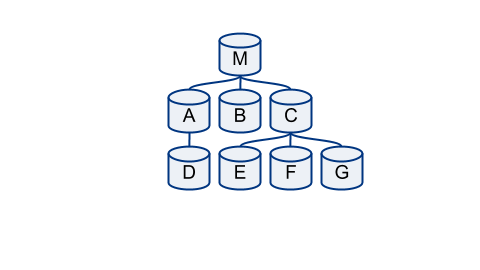
The servers E, F, G replicating from C provide us with the holistic view on C. D provides the holistic view on A.
Reducing noise
Intermediate master failover is a much simpler operation than master failover. Changing masters require name resolve changes (of some sort), whereas moving slaves around the topology affects no one.
This implies:
- We don’t mind over-reacting on failing over intermediate masters
- We pay with more noise
Sure, we don’t mind failing over D elsewhere, but as D is the only slave of A, it’s enough that D hiccups that we might get an alert (“all” intermediate master’s slaves are not replicating). To that effect orchestrator treats single slave scenarios differently than multiple slaves scenarios.
Not so fun setups and failures
At Booking.com we are in transition between setups. We have some legacy configuration, we have a roadmap, two ongoing solutions, some experimental setups, and/or all of the above combined. Sorry.
Some of our masters are on SAN. We are moving away from this; for those masters on SANs we have cold standbys in an active-passive mode; so master failure -> unmount SAN -> mount SAN on cold standby -> start MySQL on cold standby -> start recovery -> watch some TV -> go shopping -> end recovery.
Only SANs fail, too. When the master fails, switching over to the cold standby is pointless if the origin of the problem is the SAN. And given that some other masters share the same SAN… whoa. As I said we’re moving away from this setup for Pseudo GTID and then for Binlog Servers.
The SAN setup also implied using VIPs for some servers. The slaves reference the SAN master via VIP, and when the cold standby start up it assumes the VIP, and the slaves know nothing about this. Same setup goes for DC masters. What happens when the VIP goes down? MySQL is running happily, but slaves are unable to connect. Does that make for a failover scenario? For intermediate masters we’re pushing it to be so, failing over to a normal local-disk based server; this improves out confidence in non-SAN setups (which we have plenty of, anyhow).
Double checking
You sample your server once every X seconds. But in a failover scenario you want to make sure your data is up to date. When orchestrator suspects a dead master (i.e. cannot reach the master) it immediately contacts its direct slaves and checks their status.
Likewise, when orchestrator sees a first tier slave with broken IO thread, it immediately contacts the master to check if everything is fine.
For intermediate masters orchestrator is not so concerned and does not issue emergency checks.
How to fail over
Different story. Some other time. But failing over makes for complex decisions, based on who the replicating slaves are; with/out log-slave-updates; with-out GTID; with/out Pseudo-GTID; are binlog servers available; which slaves are available in which data centers. Or you may be using Galera (we’re not) which answers most of the above.
Anyway we use orchestrator for that; it knows our topologies, knows how they should look like, understands how to heal them, knows MySQL replication rules, and invokes external processes to do the stuff it doesn’t understand.
One thought on “What makes a MySQL server failure/recovery case?”