Pseudo GTID is a technique where we inject Globally Unique entries into MySQL, gaining GTID abilities without using GTID. It is supported by orchestrator and described in more detail here, here and here.
Quick recap: we can join two slaves to replicate from one another even if they never were in parent-child relationship, based on our uniquely identifiable entries which can be found in the slaves’ binary logs or relay logs. Having Pseudo-GTID injected and controlled by us allows us to optimize failovers into quick operations, especially where a large number of server is involved.
Ascending Pseudo-GTID further speeds up this process for delayed/lagging slaves.
Recap, visualized
(but do look at the presentation):
- Find last pseudo GTID in slave’s binary log (or last applied one in relay log)
- Search for exact match on new master’s binary logs
- Fast forward both through successive identical statements until end of slave’s applied entries is reached
- Point slave into cursor position on master
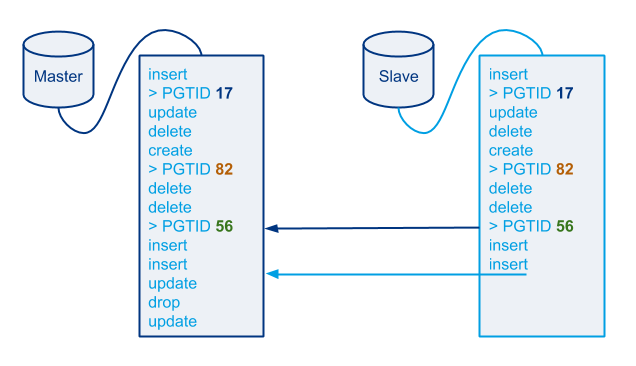
What happens if the slave we wish to reconnect is lagging? Or perhaps it is a delayed replica, set to run 24 hours behind its master?
The naive approach would expand bullet #2 into:
- Search for exact match on master’s last binary logs
- Unfound? Move on to previous (older) binary log on master
- Repeat
The last Pseudo-GTID executed by the slave was issued by the master over 24 hours ago. Suppose the master generates one binary log per hour. This means we would need to full-scan 24 binary logs of the master where the entry will not be found; to only be matched in the 25th binary log (it’s an off-by-one problem, don’t hold the exact number against me).
Ascending Pseudo GTID
Since we control the generation of Pseudo-GTID, and since we control the search for Pseudo-GTID, we are free to choose the form of Pseudo-GTID entries. We recently switched into using Ascending Pseudo-GTID entries, and this works like a charm. Consider these Pseudo-GTID entries: Continue reading » “Pseudo GTID, ASCENDING”