Orchestrator 1.2.1-beta supports Pseudo GTID (read announcement): a means to refactor the replication topology and connect slaves even without direct relationship; even across failed servers. This post illustrates two such scenarios and shows the visual way of mathcing/re-synching slaves.
Of course, orchestrator is not just a GUI tool; anything done with drag-and-drop is also done via web API (in fact, the drag-and-drop invoke the web API) as well as via command line. I’m mentioning this as this is the grounds for failover automation planned for the future.
Scenario 1: the master unexpectedly dies
The master crashes and cannot be contacted. All slaves are stopped as effect, but each in a different position. Some managed to salvage relay logs just before the master dies, some didn’t. In our scenario, all three slaves are at least caught up with the relay log (that is, whatever they managed to pull through the network, they already managed to execute). So they’re otherwise sitting idle waiting for something to happen. Well, something’s about to happen.

Note the green “Safe mode” button to the right. This means operation is through calculation of binary log files & positions with relation to one’s master. But the master is now dead, so let’s switch to adventurous mode; in this mode we can drag and drop slaves onto instances normally forbidden. At this stage the web interface allows us to drop a slave onto its sibling or any of its ancestors (including its very own parent, which is a means of reconnecting a slave with its parent). Anyhow:
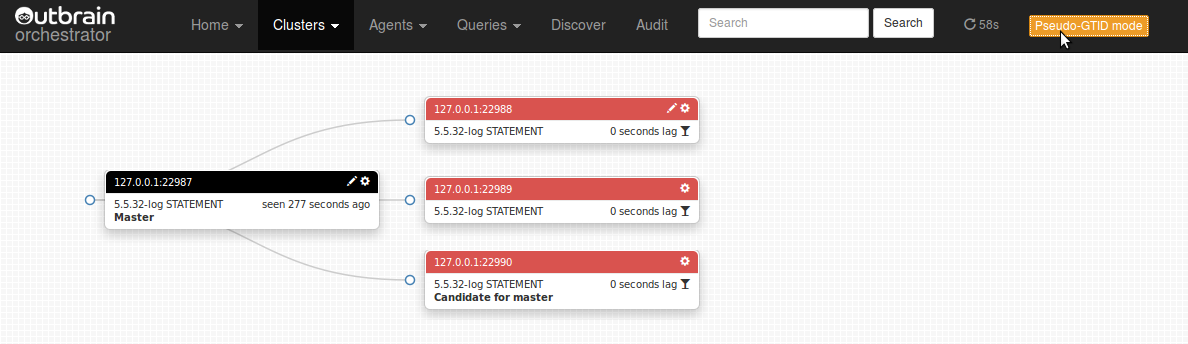
We notice that orchestrator is already kind enough to say which slave is best candidate to be the new master (127.0.0.1:22990): this is the slave (or one of the slaves) with most up-to-date data. So we choose to take another server and make it a slave of 127.0.0.1:22990:
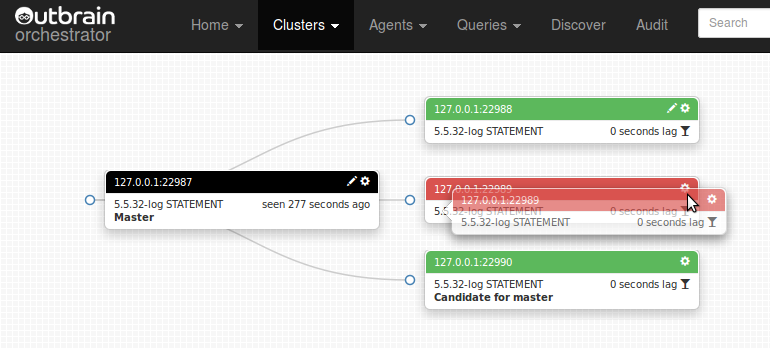
And drop:
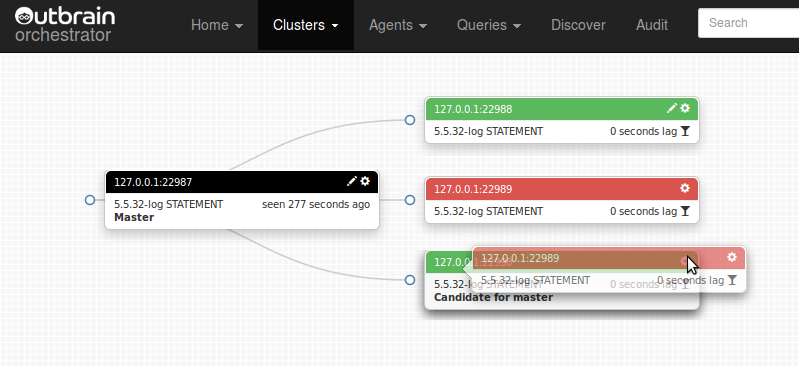
There we have it: although their shared master is inaccessible, and the two slave’s binary log file names & position mean nothing to each other, we are able to correctly match the two and make one child of the other:
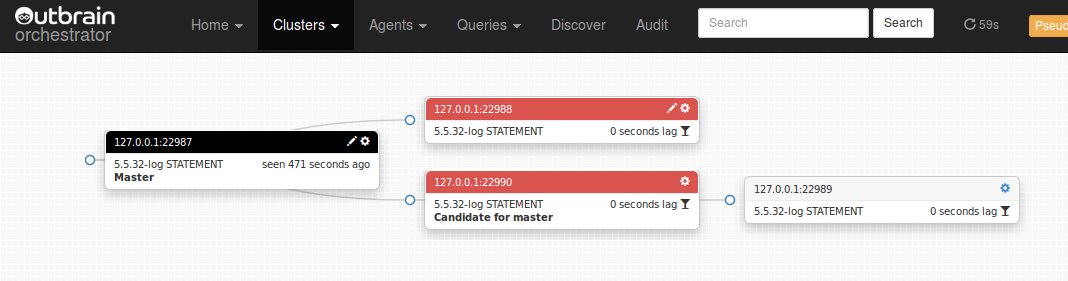
Likewise, we do the same with 127.0.0.1:22988:
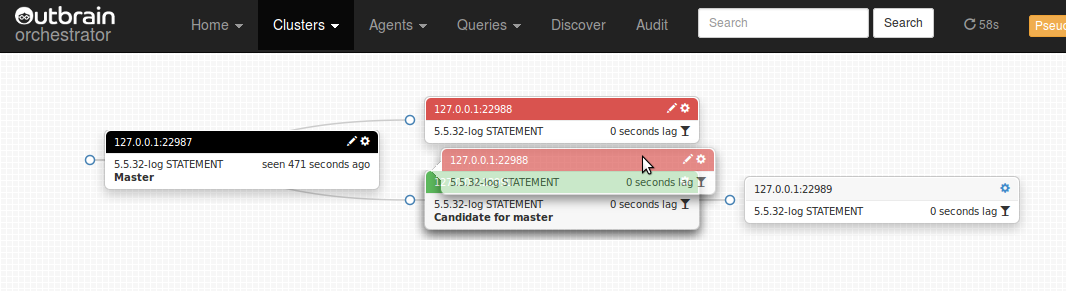
And end up with our (almost) final topology:
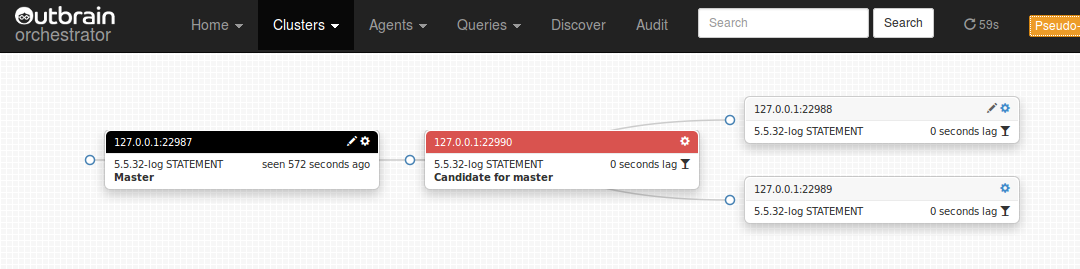
Notice how the two slaves 22988, 22989 are happily replicating from 22990. As far as they’re concerned, there is no problem in the topology any more. Now it’s your decision: do you decommission the old master? You will need to RESET SLAVE on 22990 (can do via orchestrator), turn off 22990‘s read_only (can do via orchestrator) and change DNS entries (or what have you).
Scenario 2: a local master (“relay-master”) unexpectedly dies
In this scenario we have a deep nested topology, and a local master died. What of its slaves?
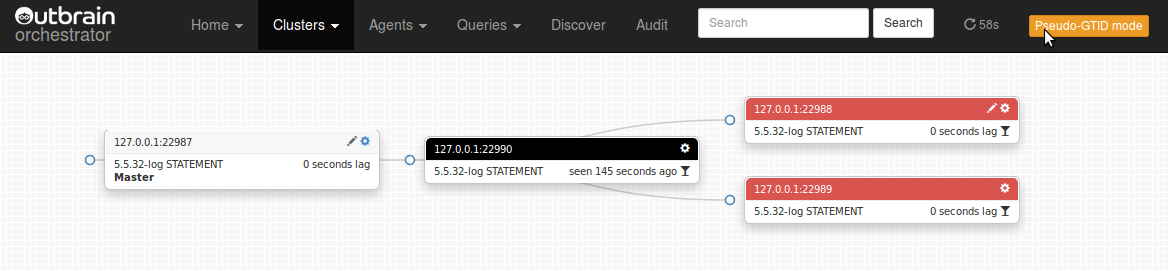
We choose one of the children and drag it over onto the master, which is up and healthy:
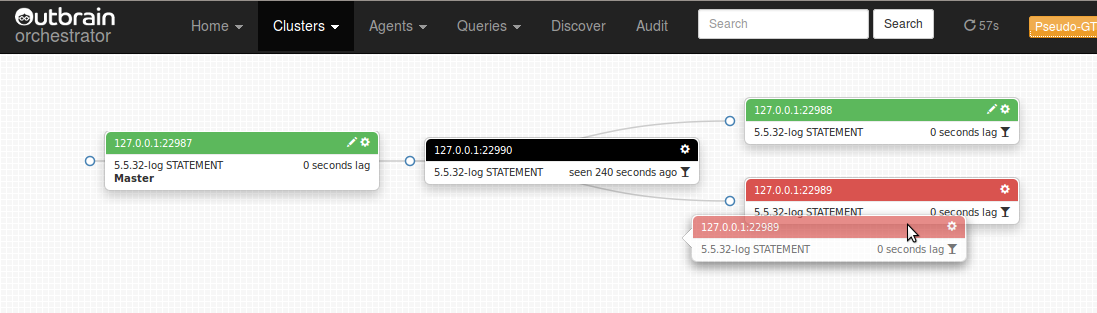
As you can see we are allowed (green instances are allowed drop places) to drop 22989 on its sibling and on its grandparent, the latter bypassing a broken connection. There is no connection between the two!
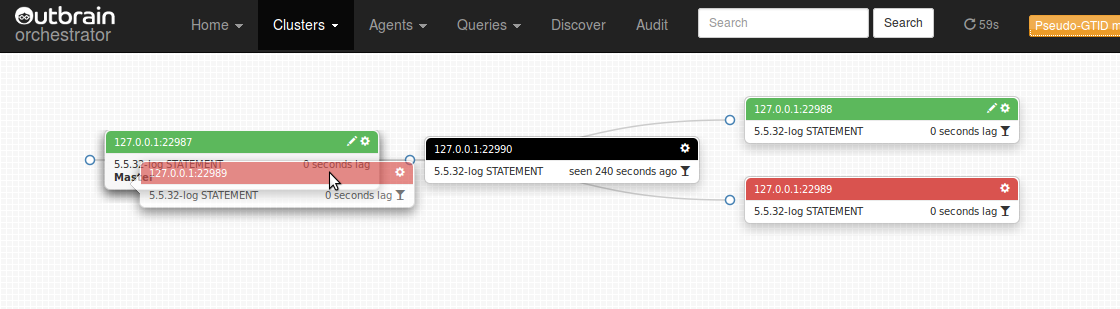
And we get a new topology:
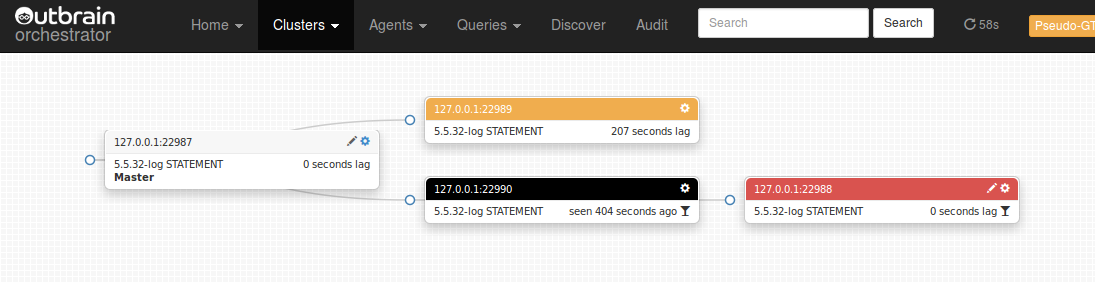
22989 is now lagging, but on the right path! Let’s do the same for 22988:
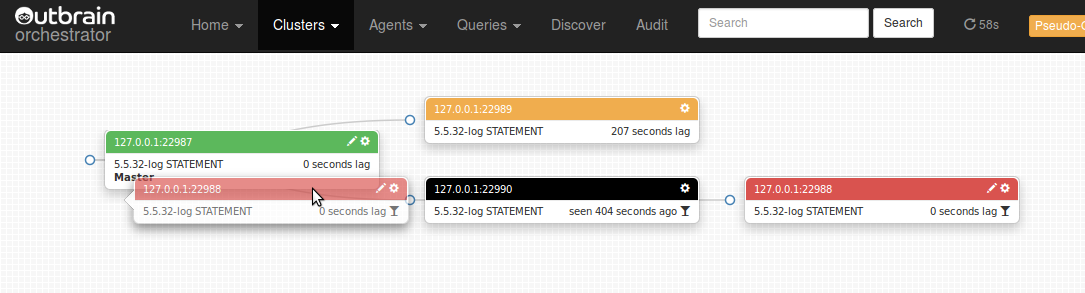
And finally:
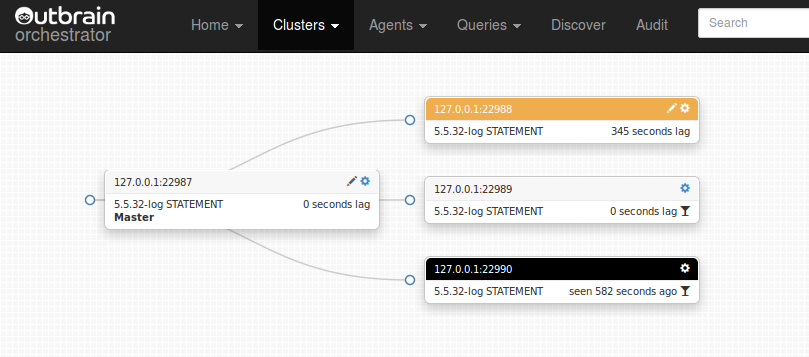
Great success! 22989 already caught up, 22988 on the way, victory is ours!
The real fun, of course, is to execute with –debug and review the DEBUG messages as orchestrator seeks, finds, matches and follows up on Pseudo GTID entries in the binary logs. We each have our pleasures.