We’re migrating some of our “vanilla” MySQL 5.5 servers to Percona Server 5.5. One of the major incentives is the crash-safe replication feature, allowing slaves to die (power failure) and resume replication without losing position in relay logs.
Whether or not we will migrate all our servers depends on further benchmarking; so far we’ve noticed unexpected results, but these are still premature to publish.
However the fact that we are using both MySQL & Percona Server has led us into a peculiar situation which I’d like to share. We reseed our servers via LVM snapshots. If we need a new machine, or have a corrupted slave, we capture an image of a running slave and duplicate it, a process which takes the better part of a day. This duplicates not only the data, of course, but also the relay logs, the relay-log.info file, master.info file, implying the position within the topology.
With crash safe replication this also means the transactional relay log position. Recap: crash safe replication writes, per transaction, the relay log status into ibdata1 file. So the relay log info in ibdata1 is in perfect alignment with your committed transactions. Upon server startup, Percona Server reads the info from ibdata1 and overwrites relay-log.info file (it completely disregards whatever was in that file prior to startup).
Can you guess what could get wrong here? Here’s the scenario we had; the same problem can unfold in different scenarios.
Take a look at the following topology:
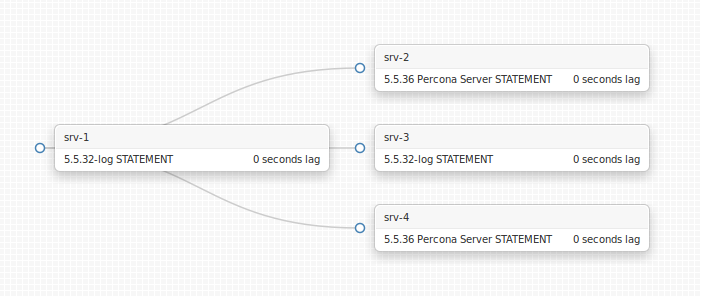
(this image is an actual online visualization of a replication topology; for purposes of this blog it’s a sandbox topology on my laptop. Please stand by for some very cool open source release announcement shortly)