This is the third post in a series of posts describing our experience in migrating a large DWH server to TokuDB (see 1st and 2nd parts). This post discusses operations; namely ALTER TABLE operations in TokuDB. We ran into quite a few use cases by this time that we can shed light on.
Quick recap: we’ve altered one of out DWH slaves to TokuDB, with the goal of migrating most of out servers, including the master, to TokuDB.
Adding an index
Shortly after migrating our server to TokuDB we noticed an unreasonably disproportionate slave lag on our TokuDB slave (red line in chart below) as compared to other slaves.
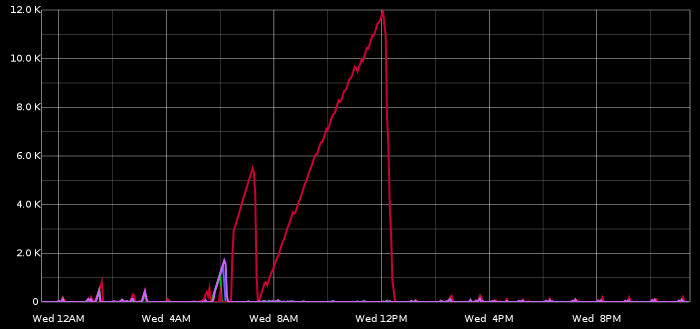
Quick investigation led to the fact that, coincidentally, a manual heavy-duty operation was just taking place, which updated some year’s worth of data retroactively. OK, but why so slow on TokuDB? Another quick investigation led to an apples vs. oranges problem: as depicted in part 1, our original setup included MONTHly partitioning on our larger tables, whereas we could not do the same in TokuDB, where we settled for YEARly partitioning.
The heavy-duty operation included a query that was relying on the MONTHly partitioning to do reasonable pruning: a WHERE condition on a date column did the right partition pruning; but where on InnoDB that would filter 1 month’s worth of data, on TokuDB it would filter 1 year.
Wasn’t it suggested that TokuDB has online table operations? I decided to give it a shot, and add a proper index on our date column (I actually created a compound index, but irrelevant).
It took 13 minutes to add an index on a 1GB TokuDB table (approx. 20GB InnoDB uncompressed equivalent):
- The ALTER was non blocking: table was unlocked at that duration
- The client issuing the ALTER was blocked (I thought it would happen completely in the background) — but who cares?
- I would say 13 minutes is fast
Not surprisingly adding the index eliminated the problem altogether.
Modifying a PRIMARY KEY
It was suggested by our DBA that there was a long time standing need to modify our PRIMARY KEY. It was impossible to achieve with our InnoDB setup (not enough disk space for the operation, would take weeks to complete if we did have the disk space). Would it be possible to modify our TokuDB tables? On some of our medium-sized tables we issued an ALTER of the form: Continue reading » “Converting an OLAP database to TokuDB, part 3: operational stuff”