I’m experimenting with upgrading to MySQL 5.6 and am experiencing an unexplained increase in disk I/O utilization. After discussing this with several people I’m publishing in the hope that someone has an enlightenment on this.
We have a few dozens servers in a normal replication topology. On this particular replication topology we’ve already evaluated that STATEMENT based replication is faster than ROW based replication, and so we use SBR. We have two different workloads on our slaves, applied by two different HAProxy groups, on three different data centres. Hardware-wise, servers of two groups use either Virident SSD cards or normal SAS spindle disks.
Our servers are I/O bound. A common query used by both workloads looks up data that does not necessarily have a hotspot, and is very large in volume. DML is low, and we only have a few hundred statements per second executed on master (and propagated through replication).
We have upgraded 6 servers from all datacenters to 5.6, both on SSD and spindle disks, and are experiencing the following phenomena:
- A substantial increase in disk I/O utilization. See a 10 day breakdown (upgrade is visible on 04/14) this goes on like this many days later:
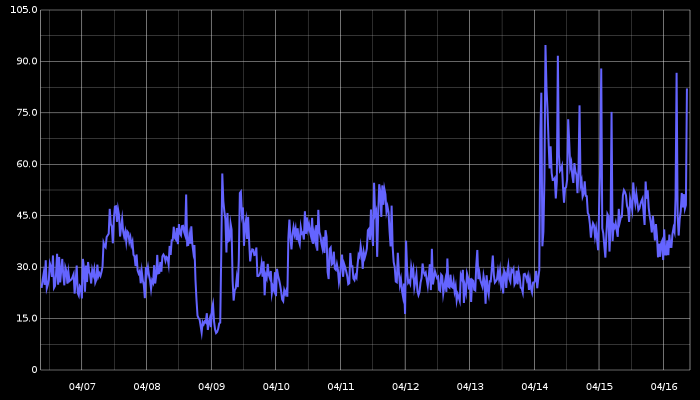
- A substantial increase in InnoDB buffer pool pages flush: Mr. Blue is our newly upgraded server; it joins Mr. Green upgraded a couple weeks ago. Mr. Red is still 5.5. This is the only MySQL graph that I could directly relate to the increase in I/O:
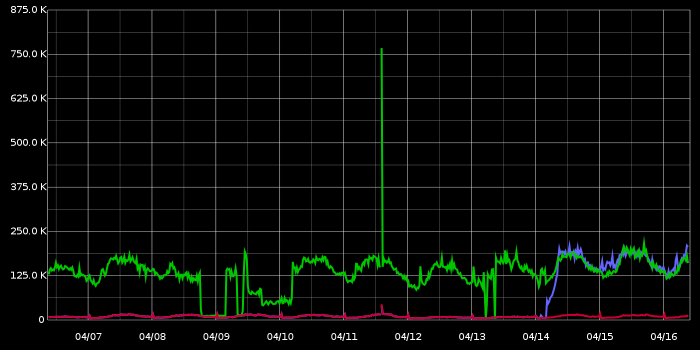
- No change in workload (it takes some 60 minutes for caches to warm up, so measuring after that time). Same equal share of serving as dictated by HAProxy. Same amount of queries. Same amount of everything.
- Faster replication speed, on single thread – that’s the good part! We see 30% and more improvement in replication speed. Tested by stopping SLAVE SQL_THREAD for a number of pre-defined minutes, then measuring time it took for slave to catch up, up to 10 seconds lag. The results vary depending on the time of day and serving workload on slaves, but it is consistently far faster with 5.6.
The faster replication speed motivates us to continue with the experiment, and is of a significant factor in our decision. However we are concerned about the I/O utilization and excessive flushing.
The above graphs depict the 5.6 status without any configuration changes as compared to 5.5. I took some days to reconfigure the following variables, with no change to the rate of flushed pages (though some changes visible in double-wite buffer writes):
- innodb_log_file_size=128M/2G
- innodb_adaptive_flushing:=0/1
- innodb_adaptive_flushing_lwm:=0/70
- innodb_max_dirty_pages_pct := 75/90
- innodb_flush_neighbors:=0/1
- innodb_max_dirty_pages_pct_lwm:=75/90
- innodb_old_blocks_time:=0/1000
- innodb_io_capacity:=50/100/200
- innodb_io_capacity_max:=50/100/1000
- relay_log_info_repository:=’table’/’file’
- master_info_repository:=’table’/’file’
- default_tmp_storage_engine:=’myisam’/’innodb’
- eq_range_index_dive_limit:=0/10
And more… Have done patient one-by-one or combinations of the above where it made sense. As you see I began with the usual suspects and moved on to more esoteric stuff. I concentrated on new variables introduced in 5.6, or ones where the defaults have changed, or ones we have explicitly changed the defaults from.
The above is consistent on all upgraded servers. On SSD the disk utilization is lower, but still concerning.
Our use case is very different from the one presented by Yoshinori Matsunobu. and apparently not too many have experienced upgrading to 5.6. I’m hoping someone might shed some light.
[posting on behalf of Dimitri; SN]
what is great that since MySQL 5.6 there is more and more instrumentation generally present in the code and yet more in InnoDB via its METRICS table.
so, let’s try to understand first from where the suspected flushing is coming..
first of all you have to enable METRICS counters :
mysql> set global innodb_monitor_enable = ‘%’
(or just have innodb_monitor_enable=’%’ in your my.conf file on startup)
then, using information_schema, start to monitor your flushing activity :
(of course more helpful will be to get the diff/sec graphed from these values to see the tendency)..
once you’ll have an idea to which flush processing your IO activity is related, you may then get a look on all %flush% counters, etc..
Laurynas, Dimitry,
thanks both – will take further measurement and report.
Hair turning grey. After some hunting, I came upon this:
At this stage I will stop 5.6 evaluation and wait for higher forces to put sense into life. Have submitted bug report: http://bugs.mysql.com/bug.php?id=72423
For completeness, it seems like the buffer_pool_pages_* weird values are actually valid, according to this: http://bugs.mysql.com/bug.php?id=59550 (compressed pages are counted inconsistently with total num pages the way I understand it)
It’s ironic how in the MySQL Doc on “Controlling the Flushing Rate of Dirty Pages from the InnoDB Buffer Pool” reads a little differently of late.
MySQL 5.5 says : InnoDB performs certain tasks in the background, including flushing of dirty pages (those pages that have been changed but are not yet written to the database files) from the buffer pool, a task performed by the master thread. Currently, InnoDB aggressively flushes buffer pool pages if the percentage of dirty pages in the buffer pool exceeds innodb_max_dirty_pages_pct.
MySQL 5.6 says : InnoDB performs certain tasks in the background, including flushing of dirty pages (those pages that have been changed but are not yet written to the database files) from the buffer pool. Currently, InnoDB flushes buffer pool pages if the percentage of dirty pages in the buffer pool exceeds innodb_max_dirty_pages_pct.
Interstng how the MySQL 5.6 Doc does not say “aggressively”. Maybe something did change.
Someone should look into whether the introduction of innodb_flush_neighbors may have altered the way flushing is evaluated and subsequently performed.
The option innodb_flush_neighbors was introduced in MySQL 5.6. It’s default behavior to flush contiguous dirty pages.
MySQL 5.5 flushing can rightly be called “aggressive” if it flushes anything dirty in the buffer pool, contiguous or not.
MySQL 5.6 is supposed to be conservative in its default innodb_flush_neighbors setting. If the flushing algorithm has to look for contiguous dirty pages only, there should be reason for excessive flushing.
If this algorithm is faulty and not properly taking innodb_max_dirty_pages_pct in account, this excessive flushing could possibly be a manifestation of such code.
Of course, all this is just my conjecture. Notwithstanding, I would like to see what your submitted bug report turns up.