This post describes in detail the method of using Pseudo GTID to achieve unplanned replication topology changes, i.e. connecting two arbitrary slaves, or recovering from a master failure even as all its slaves are hanging in different positions.
Please read Pseudo GTID and Pseudo GTID, RBR as introduction.
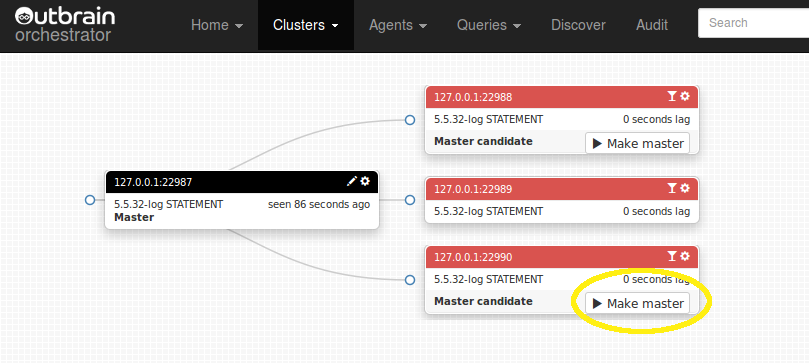
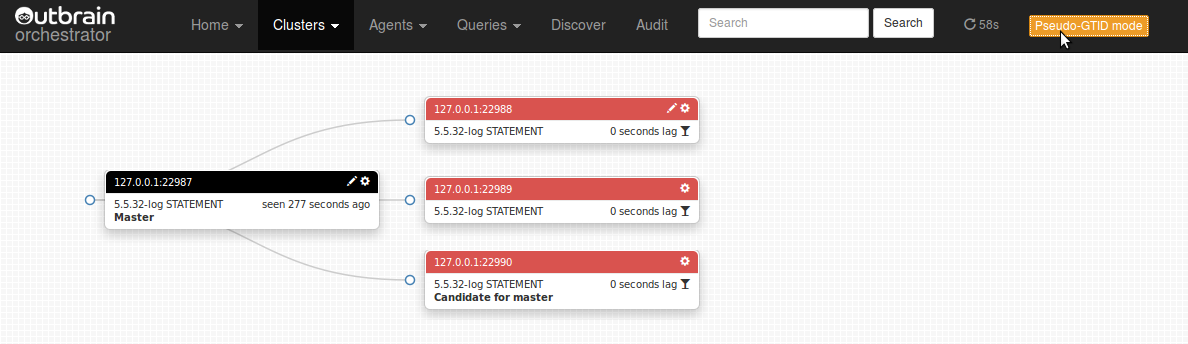
Consider the following case: the master dies unexpectedly, and its three slaves are all hanging, not necessarily at same binary log file/position (network broke down while some slaves managed to salvage more entries into their relay logs than others)

(Did you notice the “Candidate for master” message? To be discussed shortly)
GTID
With GTID each transaction (and entry in the binary log) is associated with a unique mark — the Global Transaction ID. Just pick the slave with the most advanced GTID to be the next master, and just CHANGE MASTER TO MASTER_HOST=’chosen_slave’ on the other slaves, and everything magically works. A slave knows which GTID it has already processed, and can look that entry on its master’s binary logs, resuming replication on the one that follows.
How does that work? The master’s binary logs are searched for that GTID entry. I’m not sure how brute-force this is, since I’m aware of a subtlety which requires brute-force scan of all binary logs; I don’t actually know if it’s always like that.
Pseudo GTID
We can mimick that above, but our solution can’t be as fine grained. With the injection of Pseudo GTID we mark the binary log for unique entries. But instead of having a unique identifier for every entry, we have a unique identifier for every second, 10 seconds, or what have you, with otherwise normal, non-unique entries in between our Pseudo GTID entries.
Recognizing which slave is more up to date
Given two slaves, which is more up to date?
- If both replicate(d) from same master, a SHOW SLAVE STATUS comparison answers (safe method: wait till SQL thread catches up with broken IO thread, compare relay_master_log_file, exec_master_log_pos on both machines). This is the method by which the above “Candidate for master” message is produced.
- If one is/was descendent of the other, then obviously it is less advanced or equals its ancestor.
- Otherwise we’re unsure – still solvable via bi-directional trial & error, as explained later on.
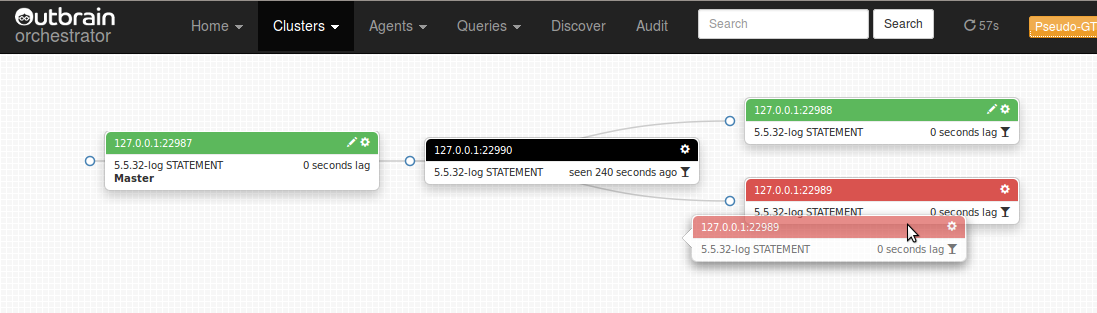
For now, let’s assume we know which slave is more up to date (has received and executed more relay logs). Let’s call it S1, whereas the less up-to-date will be S2. This will make our discussion simpler. Continue reading » “Refactoring replication topology with Pseudo GTID”