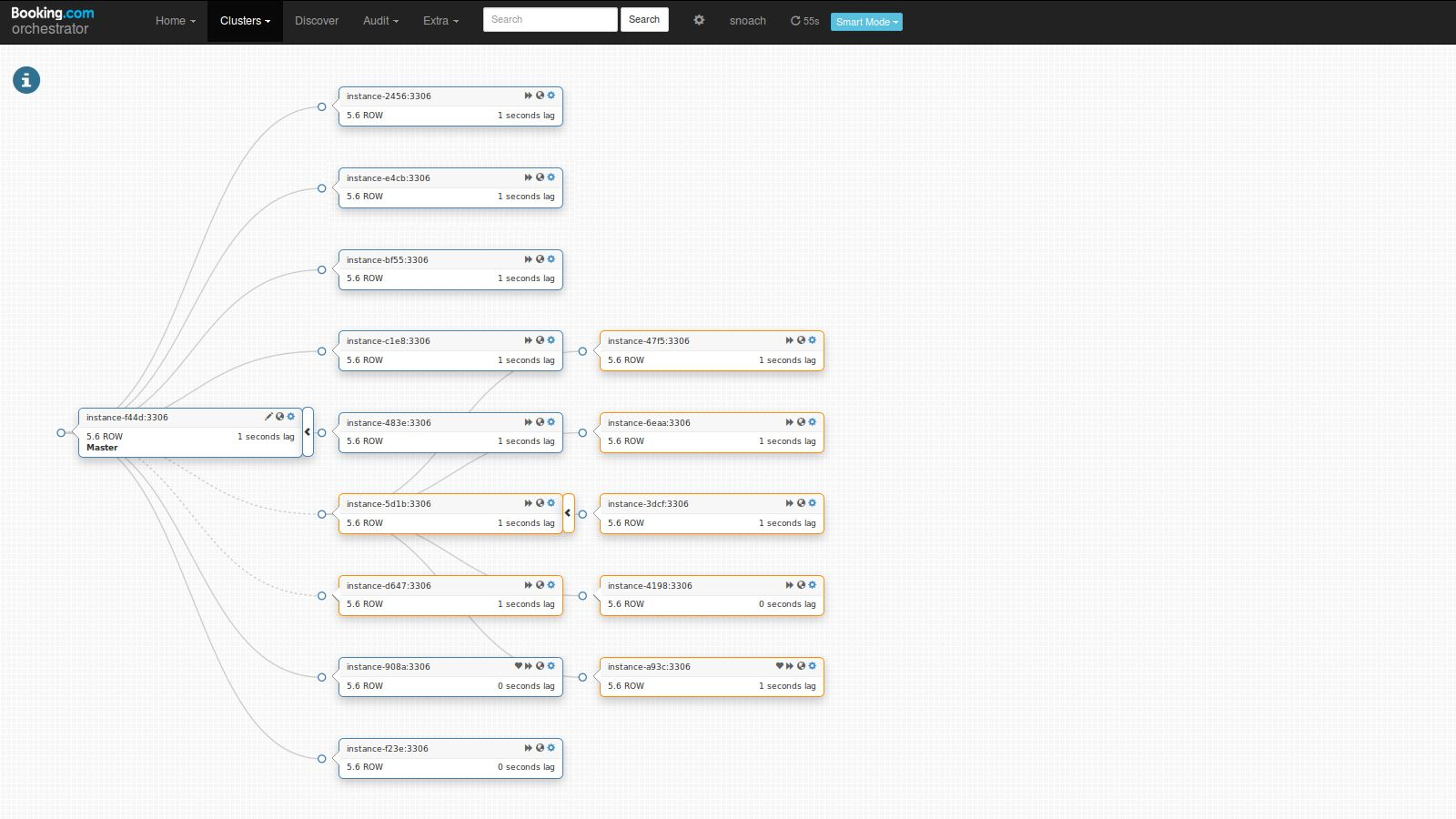
One of our internal apps at Booking.com audits changes to our tables on various clusters. We used to use tungsten replicator, but have since migrated onto our own solution.
We have a binlog reader (uses open-replicator) running on a slave. It expects Row Based Replication, hence our slave runs with log-slave-updates, binlog-format=’ROW’, to translate from the master’s Statement Based Replication. The binlog reader reads what it needs to read, audits what it needs to audit, and we’re happy.
However what happens if that slave dies?
In such case we need to be able to point our binlog reader to another slave, and it needs to be able to pick up auditing from the same point.
This sounds an awful lot like slave repointing in case of master/intermediate master failure, and indeed the solutions are similar. However our binlog reader is not a real MySQL server and does not understands replication. It does not really replicate, it just parses binary logs.
We’re also not using GTID. But we are using Pseudo-GTID. As it turns out, the failover solution is already built in by orchestrator, and this is how it goes:
Normal execution
Our binlog app reads entries from the binary log. Some are of interest for auditing purposes, some are not. An occasional Pseudo-GTID entry is found, and is being stored to ZooKeeper tagged as “last seen and processed Pseudo-GTID”.
Upon slave failure
We recognize the death of a slave; we have other slaves in the pool; we pick another. Now we need to find the coordinates from which to carry on.
We read our “last seen and processed Pseudo-GTID”. Say it reads:
drop view if exists `meta`.`_pseudo_gtid_hint__asc:56373F17:00000000012B1C8B:50EC77A1`
. We now issue:
$ orchestrator -c find-binlog-entry -i new.slave.fqdn.com --pattern='drop view if exists `meta`.`_pseudo_gtid_hint__asc:56373F17:00000000012B1C8B:50EC77A1`'
The output of such command are the binlog coordinates of that same entry as found in the new slave’s binlogs:
binlog.000148:43664433
Pseudo-GTID entries are only injected once every few seconds (5 in our case). Either: Continue reading » “Orchestrator & Pseudo-GTID for binlog reader failover”